进程与线程之间关系
一个进程对应一个程序的执行,它具有文本、数据、堆栈片段以及它自己的资源;而一个线程则是进程执行过程中的一个单独的执行序列,线程有时候也被称为轻量级进程. 一个进程可以包含多个线程,这些线程共享进程的资源。
首先我们明确一点,就是我们创建的每一个Java程序都是运行在一个单独的Java虚拟机进程中的,每启动一个java程序就会同时开启一个单独对应的JVM进程(也叫做JVM实例),然后JVM进程会开始初始化类,包括初始化静态变量和静态代码块,普通变量,构造器等;然后再去寻找main()主线程作为程序执行入口,继续执行其他线程直至结束.(Android应用程序和dalvik虚拟机的关系也一样如此)
常见的进程间通信方式(IPC)
- 管道与命名管道:管道允许一个进程和另一个与它有共同祖先的进程之间进行通信,命名管道允许无亲缘关系的进程间的通信,命名管道在文件系统中有对应的文件名,通过命令mkfifo或系统调用mkfifo来创建
- 套接字:可用于不同机器之间的进程间通信
- 共享内存:多个进程可以访问同一块内存空间,是最快的可用IPC形式
- 文件内存映射:内存映射允许任何多个进程间通信,每一个使用该机制的进程通过把一个共享的文件映射到自己的进程地址空间来实现它; 需要文件锁做同步
- 信号量:主要作为进程间以及同一进程不同线程之间的同步手段
- 信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身
- 消息队列:消息队列是消息的链接表,包括Posix消息队列和system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息
进程的状态:就绪-运行-阻塞

多线程之间通信方式
- “共享变量”:实现Runnable接口实现线程的共享变量或者内部类共享外围类的变量
“管道流”:
/* 管道输出流和生产者线程绑定, 管道输入流和消费者线程绑定,输入输出流绑定,启动两个线程互相之间通过write和read函数就行通信 */ PipedOutputStream pos = new PipedOutputStream(); Producer p = new Producer(pos); PipedInputStream pis = new PipedInputStream(); Consumer c = new Consumer(pis); pos.connect(pis); p.start(); c.start(); class Producer extends Thread { private PipedOutputStream pos; public Producer(PipedOutputStream pos) { this.pos = pos; } public void run() { int i = 8; try { pos.write(i); // pis.read() } catch (IOException e) { e.printStackTrace(); } } }
线程的四种创建方式
- 定义Thread类的子类,并重写该类的run()方法;创建Thread子类的实例,即创建了线程对象,调用线程对象的start()方法来启动该线程
- 定义Runnable接口的实现类,并重写该接口的run()方法,创建Runnable实现类的实例,并以此实例作为Thread的参数来创建Thread对象,该Thread对象才是真正的线程对象;然后调用线程对象的start()方法来启动线程
创建Callable接口的实现类,并实现call()方法,该call()方法有返回值;创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值,使用FutureTask对象作为Thread对象的target创建并启动新线程,调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
public class MyCallableTest implements Callable<Integer>{ // 实现call方法,作为线程执行体 public Integer call(){ int i = 0; for ( ; i < 100 ; i++ ){ System.out.println(Thread.currentThread().getName()+ "\t" + i); } // call()方法可以有返回值,而且可以抛出异常 return i; } public static void main(String[] args) { // 创建Callable对象 MyCallableTest myCallableTest = new MyCallableTest(); // 使用FutureTask来包装Callable对象 FutureTask<Integer> task = new FutureTask<Integer>(myCallableTest); for (int i = 0 ; i < 100 ; i++){ System.out.println(Thread.currentThread().getName()+ " \t" + i); if (i == 20){ // 实质还是以Callable对象来创建、并启动线程 new Thread(task , "callable").start(); // 线程池执行FutureTask Executor executor = Executors.newSingleThreadExecutor(); executor.execute(task); } } try{ // 获取线程返回值 System.out.println("callable返回值:" + task.get()); } catch (Exception ex){ ex.printStackTrace(); } } }线程池:
- 线程池的好处1在于可以更好地控制并发线程数目,提高资源利用率并防止阻塞
- 好处2可以更好地重用线程, 减少线程创建和销毁带来的系统开销,可以设置线程定时定期执行
- 核心构造函数ThreadPoolExecutor,可以在参数中设置核心池大小,最大线程数等
- ExecutorService接口用于实现和管理线程池,其生命周期包括三种状态:运行、关闭、终止。
- 线程池四个基本组成部分:
- 线程池管理器(ThreadPool):用于创建并管理线程池,包括 创建线程池,销毁线程池,添加新任务;
- 工作线程(PoolWorker):线程池中线程,在没有任务时处于等待状态,可以循环的执行任务;
- 任务接口(Task):每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等;
- 任务队列(taskQueue):用于存放没有处理的任务, 提供一种缓冲机制。
四种Executors接口提供的通过ThreadFactory新建的线程池
newFixedThreadPool(): 固定数目线程池,任意时间点最多只能有固定数目的活动线程存在;有新任务到达时创建线程,只能放在另外的队列中等待,直到达到线程池最大大小为止,有异常则补充
ExecutorService threadPool = Executor.newFixedThreadPool(3); Runnable r = new Runnable() { @Override public void run() { } }; // 参数可以是Thread以及Runnable对象 threadPool.execute(r);newCachedThreadPool:缓存型线程池,新任务到达则新建线程,当线程数目大于处理需要时,则回收空闲的线程,无大小限制
- newSingleThreadExecutor: 单线程池,只创建唯一的工作线程来执行任务,保证任务被顺序执行
- newScheduledThreadPool: 调度型线程池,固定线程数目,而且提供任务被定时和周期性执行的功能
自定义线程池
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) /* corePoolSize - 核心池中所保存的线程数,包括空闲线程;也就是正在运行的线程数目。 maximumPoolSize-线程池中允许的最大线程数 keepAliveTime - 当线程池的工作线程空闲后,保持存活的时间 unit - keepAliveTime 参数的时间单位 workQueue - 执行前用于保持任务的队列。此队列仅保持由 execute方法提交的 Runnable任务 threadFactory - 执行程序创建新线程时使用的工厂 handler - 由于超出线程范围和队列容量而使新到达的任务被阻塞时采取的处理策略, 默认为AbortPolicy,表示无法处理新任务时抛出异常;DiscardPolicy:不能执行的任务将被删除 ThreadPoolExecutor是Executors类的底层实现 */ public class ThreadPoolTest{ public static void main(String[] args){ //创建等待队列 BlockingQueue<Runnable> bqueue = new ArrayBlockingQueue<Runnable>(20); //创建线程池,池中保存的线程数为3,允许的最大线程数为5 ThreadPoolExecutor pool = new ThreadPoolExecutor(3,5,50,TimeUnit.MILLISECONDS,bqueue); //创建七个任务 Runnable t1 = new MyThread(); Runnable t2 = new MyThread(); Runnable t3 = new MyThread(); Runnable t4 = new MyThread(); Runnable t5 = new MyThread(); Runnable t6 = new MyThread(); Runnable t7 = new MyThread(); //每个任务会在一个线程上执行 pool.execute(t1); pool.execute(t2); pool.execute(t3); pool.execute(t4); pool.execute(t5); pool.execute(t6); pool.execute(t7); //关闭线程池 pool.shutdown(); } } class MyThread implements Runnable{ @Override public void run(){ System.out.println(Thread.currentThread().getName() + "正在执行。。。"); try{ Thread.sleep(100); }catch(InterruptedException e){ e.printStackTrace(); } } }- 线程池工作流程
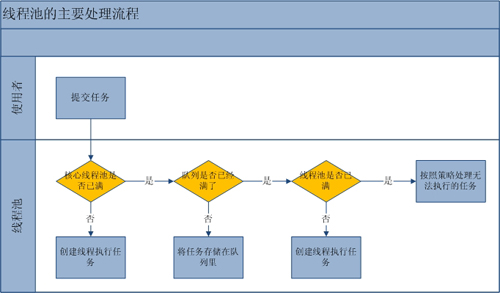
线程池的排队策略
- 默认选项是SynchronousQueue,它将任务直接提交给线程而不保持它们,一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态
- 无界队列。使用无界队列(例如,不具有预定义容量的 LinkedBlockingQueue)将导致在所有 corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程就不会超过corePoolSize。(因此,maximumPoolSize的值也就无效了。)当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
- 有界队列。当使用有限的 maximumPoolSizes时,有界队列(如 ArrayBlockingQueue)有助于防止资源耗尽,但是可能较难调整和控制。队列大小和最大池大小可能需要相互折衷:使用大型队列和小型池可以最大限度地降低 CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如,如果它们是 I/O边界),则系统可能为超过您许可的更多线程安排时间。使用小型队列通常要求较大的池大小,CPU使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量。
- PriorityBlockingQueue: 一个具有优先级的无限阻塞队列
线程池的风险
- 死锁: 死锁的产生是因为一组线程或者进程互相等待资源的释放而永远互相等待;线程池中容易产生一种新的死锁: 当核心池中所有线程都在等待阻塞队列中的某个线程的执行结果,但是该线程却因为池中没有空闲线程而没有办法执行,这样就导致互相等待的死锁.
- 并发错误: 线程池和其它排队机制依靠使用 wait() 和 notify() 方法,易出现问题
线程池的执行: execute和submit两个方法都可以向线程池提交任务, execute()方法的返回类型是void,它定义在Executor接口中;submit()方法可以返回持有计算结果的Future对象,它定义在ExecutorService接口中,它扩展了Executor接口,便于捕获异常,利用FutureTask.get()函数
线程池的关闭
- 通过调用线程池的shutdown或shutdownNow方法来关闭线程池,它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。但是它们存在一定的区别,shutdownNow首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表,而shutdown只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程。
- 只要调用了这两个关闭方法的其中一个,isShutdown方法就会返回true。当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminaed方法会返回true。至于我们应该调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性决定,通常调用shutdown来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow。
- 合理配置线程池
- 任务的性质:CPU密集型任务,IO密集型任务和混合型任务;CPU密集型任务配置尽可能小的线程,如配置Ncpu+1个线程的线程池。IO密集型任务则由于线程并不是一直在执行任务,则配置尽可能多的线程,如2*Ncpu
- 任务的优先级:高,中和低;PriorityBlockingQueue会导致优先级低的线程永远不被执行
- 任务的执行时间:长,中和短;
- 任务的依赖性:是否依赖其他系统资源,如数据库连接:依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,如果等待的时间越长CPU空闲时间就越长,那么线程数应该设置越大,这样才能更好的利用CPU。
线程的状态变化
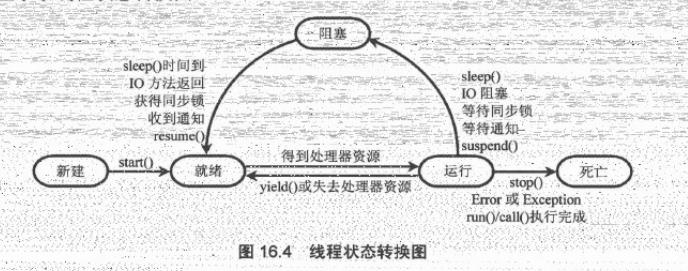
死锁及其解决办法
/**
* 一个简单的死锁类 当DeadLock类的对象flag==1时(td1),先锁定o1,睡眠500毫秒
* 而td1在睡眠的时候另一个flag==0的对象(td2)线程启动,先锁定o2,睡眠500毫秒
* td1睡眠结束后需要锁定o2才能继续执行,而此时o2已被td2锁定; td2睡眠结束后需要锁定o1才能继续执行,而此时o1已被td1锁定;
* td1、td2相互等待,都需要得到对方锁定的资源才能继续执行,从而死锁
*/
public class DeadLock implements Runnable {
public int flag = 1;
// 静态对象是类的所有对象共享的
private static Object o1 = new Object(), o2 = new Object();
public void run() {
System.out.println("flag=" + flag);
if (flag == 1) {
synchronized (o1) {
System.out.println("thread1锁定 o1");
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
// thread1等待资源o2释放
synchronized (o2) {
System.out.println("1");
}
}
}
if (flag == 2) {
synchronized (o2) {
System.out.println("thread2锁定 o2");
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
// thread2等待资源o1释放
synchronized (o1) {
System.out.println("2");
}
}
}
}
public static void main(String[] args) {
DeadLock td1 = new DeadLock();
DeadLock td2 = new DeadLock();
td1.flag = 1;
td2.flag = 2;
// td1,td2都处于可执行状态,但JVM线程调度先执行哪个线程是不确定的。
// td2的run()可能在td1的run()之前运行
new Thread(td1).start();
new Thread(td2).start();
}
}
- 死锁的必要条件死锁是指是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待对方占有的资源的现象,若无外力作用,它们都将无法推进下去。
- 互斥条件:指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
- 请求和保持条件:指进程请求新资源发生阻塞时对自己已经获得的其它资源保持不放。
- 不剥夺条件:指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
- 环路等待条件:指在发生死锁时,进程之间会形成一种头尾相接的循环等待资源关系,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源。
- 死锁的避免、预防和解决方法
- 采用资源有序分配法,破坏环路等待形成
- 允许进程剥夺其他进程占有的资源
- 银行家算法:把操作系统看作是银行家,操作系统管理的资源相当于银行家管理的资金,进程向操作系统请求分配资源相当于用户向银行家贷款。操作系统按照银行家制定的规则为进程分配资源,当进程首次申请资源时,要测试该进程对资源的最大需求量,如果系统现存的资源可以满足它的最大需求量则按当前的申请量分配资源,否则就推迟分配。当进程在执行中继续申请资源时,先测试该进程已占用的资源数与本次申请的资源数之和是否超过了该进程对资源的最大需求量。若超过则拒绝分配资源,若没有超过则再测试系统现存的资源能否满足该进程尚需的最大资源量,若能满足则按当前的申请量分配资源,否则也要推迟分配。
- 互斥条件无法被破坏
多线程相关问题
- yield表示暂停当前线程,执行其他线程(包括自身线程)由cpu决定
- join:阻塞所在线程,等调用它的线程执行完毕,再向下执行
- sleep()方法属于Thread类中的,而wait()方法则是属于Object类;sleep()方法导致了程序暂停执行指定的时间,让出cpu给其他线程,但是他的监控状态依然保持,当指定的时间到了又会自动恢复运行状态,线程不会释放对象锁;而当调用wait()方法的时候,线程会放弃对象锁,只有针对此对象调用notify()方法后本线程才进入对象锁定池准备就绪
多线程同步的方法
- Synchronized代码块
- Synchronized方法
- RetrantLock可重入锁
- ThreadLocal线程局部变量
- Volatile可见变量