自我介绍 1min 慢,停顿
- 姓名 —-> 学习经历(中大科大软件专业) 基于兴趣和职业规划 —-> 本科到硕士都注重计算机基础知识积累,对Java语言基础,计算机网络/MySQL数据库原理,常见数据结构和算法比较熟悉,例如常见排序,链表,二叉树,队列栈等;平常对移动端和web端研发也具有浓厚兴趣
- 一直以来也比较注重实践,陆续参加了几个实习和项目,提现学习和工作能力(先后参与3份实习和2个校内科研项目,选择与岗位相符的两段经历进行1-2句话简述,做了什么和达到了什么成就)
- 业余爱好,羽毛球,健身,阅读和利用coursera进行业余学习
- 对目标岗位的理解和想法,应聘该岗位的强烈意愿以及自身吻合度
- 经历:前期社会活动兴趣的广泛性+后期对专业的专注性;性格:程序员中的外向型
网易
- 学习Spring框架使用和原理
- 接口实现
- 网易实习时有挑战性的地方以及,最大的贡献
- 自己扮演的角色应该是需求开发者和主动学习者的角色 ①快速学习能力的体现以及快速学习的方法,学习使用redis,Spring框架开发restful 数据接口②沟通与合作:与产品,前端,测试之间分工合作②贡献818的部分核心需求,开奖时服务端通过张连接WebSocket主动推送给app开奖信息;设置一个观察者观察开奖数据;然后查表中未中奖用户的信息进行推送
Kactus
- ECO餐厅食用油回收系统
- Android端缓存机制的实现,采用二级缓存,LRUcache内存缓存和DiskLruCache文件缓存,同时模拟浏览器缓存机制来分析http请求过程的请求头内容来确定cache-control策略
- App请求server数据流程: 当我们第一次打开应用获取图片时,先到网络去下载图片,然后依次存入内存缓存,磁盘缓存;以后每次加载图片的时候都优先去LRUCache内存缓存当中读取,当读取不到的时候则回去DiskLruCache硬盘缓存中读取,而如果硬盘缓存仍然读取不到的话,就从网络上请求原始数据。
- App的二级缓存实现: 变化频繁的小数据(例如订单列表)都采用LRUCache,以
- 缓存管理和清理策略:
- ① 现用方法App根据服务器响应头部里边的expires(缓存过期的时间(绝对时间)),Last-Modified(服务器响应的资源最终修改时间), Cache-Control(资源的有效期)等内容来确定是否需要将数据缓存到DiskLruCache中,以及缓存的保留时间,具体实现 每次请求url得到响应结果时会解析头部Cache-Control去判断该响应资源是否需要缓存以及缓存过期时间等内容;然后将资源URL和这些缓存时间相关的http头部信息(比如expires(缓存过期的时间))一起存储到SQLite数据库,然后每次加载资源都会先根据url查询数据库看本地缓存是否过期,是否需要重新发送网络请求并更新缓存
- ② 其它方法每次去读取缓存文件时先调用File.lastModified()方法得到文件的最后修改时间,与当前时间相减得到已缓存时间,然后根据自定义的缓存时间判断该缓存是否过期,如果过期则重新请求文件,不然直接从缓存加载,这样就能实现缓存文件定时清理
- ③ 每次服务器资源变化时客户端怎么得到通知?, 客户端定时轮询请求某个指定url并解析返回的json判断某些数据是否变化,变化就重新请求该数据; 或者手动刷新,socket长连接
- FIFOFirst In First Out,先进先出;核心原则就是:如果一个数据最先进入缓存中,则应该最早淘汰掉。也就是说,当缓存满的时候,应当把最先进入缓存的数据给淘汰掉。
- LFU:Least Frequently Used,最不经常使用;在一段时间内,数据被使用次数最少的,优先被淘汰。
- LRU: Least Recently Used,最近最少使用策略,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”;简单的说就是缓存一定量的数据,当超过设定的阈值时就把一些最近最少使用的数据删除掉;最常见的实现算法是使用一个链表保存缓存数据,①新数据插入到链表头部;②每当缓存命中(即缓存数据被访问),则将数据移到链表头部;③当链表满的时候,将链表尾部的数据丢弃。LRUCache双向链表+HashMap实现 LRUCache LinkedHashMap实现
- LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。实现:相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据
- Android端缓存机制的实现,采用二级缓存,LRUcache内存缓存和DiskLruCache文件缓存,同时模拟浏览器缓存机制来分析http请求过程的请求头内容来确定cache-control策略
缓存图片举例:
// 获取应用可占内存的1/8作为缓存
int maxSize = (int) (Runtime.getRuntime().maxMemory() / 8);
// 实例化LruCaceh对象
mLruCache = new LruCache<String, Bitmap>(maxSize) {
@Override
protected int sizeOf(String key, Bitmap bitmap) {
return bitmap.getRowBytes() * bitmap.getHeight();
}
};
mDiskLruCache=DiskLruCache.open(getDiskCacheDir(context.getApplicationContext(),
"xxxxx"), getAppVersion(context), 1, DISKMAXSIZE);
// 缓存操作
mLruCache.get(url);
mLruCache.put(url, bitmap);
bitmap = BitmapFactory.decodeStream(mDiskLruCache.get(url).getInputStream(0));
DiskLruCache.Editor editor = mDiskLruCache.edit(key);
OutputStream outputStream = editor.newOutputStream(0);
editor.commit();
采用Java WebSocket编程取代传统的非实时http请求连接模式
为什么要用WebSocket实时交互数据?: 传统Web应用的信息交互过程通常是客户端发出一个请求,服务器端接收和审核完请求后进行处理并返回结果给客户端,然后客户端浏览器将信息呈现出来,但是对于那些实时要求比较高的应用来说,比如说在线游戏、新闻在线播报、RSS 订阅推送等等,当客户端浏览器准备呈现这些信息的时候,这些信息在服务器端可能已经过时了;所以我们考虑采用webSocket 常见的模拟实时应用方法
轮询:最早的一种实现实时 Web 应用的方案。客户端以一定的时间间隔向服务端发出请求,以频繁请求的方式来保持客户端和服务器端的同步。服务器端的数据可能并没有更新但是依然请求,会带来很多无谓的网络传输,所以这是一种非常低效的实时方案。
长轮询:为了降低无效的网络传输,当服务器端没有数据更新的时候,连接会保持一段时间周期直到数据或状态改变或者时间过期,通过这种机制来减少无效的客户端和服务器间的交互
流: 流技术方案通常就是在客户端的页面使用一个隐藏的窗口向服务端发出一个长连接的请求。服务器端接到这个请求后作出回应并不断更新连接状态以保证客户端和服务器端的连接不过期。通过这种机制可以将服务器端的信息源源不断地推向客户端。这种机制需要针对不同的浏览器设计不同的方案来改进用户体验,同时这种机制在并发比较大的情况下,对服务器端的资源是一个极大的考验。
WebSocket原理和建立过程: WebSocket是一个基于TCP连接的双向通道;为了建立一个 WebSocket 连接,客户端浏览器首先要向服务器发起一个 HTTP 请求,这个请求和通常的 HTTP 请求不同,包含了一些附加头信息,其中附加头信息”Upgrade: WebSocket”表明这是一个申请协议升级的 HTTP 请求,服务器端解析这些附加的头信息然后产生应答信息返回给客户端,客户端和服务器端的 WebSocket 连接就建立起来了,双方就可以通过这个连接通道自由的传递信息,并且这个连接会持续存在直到客户端或者服务器端的某一方主动的关闭连接。
@ServerEndpoint("/websocket") public class WebSocketTest { @OnMessage public void onMessage(String message, Session session) throws IOException, InterruptedException { System.out.println("Received: " + message); // Send the first message to the client session.getBasicRemote().sendText("This is the first server message"); // Send 3 messages to the client every 5 seconds int sentMessages = 0; while(sentMessages < 3){ Thread.sleep(5000); session.getBasicRemote(). sendText("This is an intermediate server message. Count: " + sentMessages); sentMessages++; } // Send a final message to the client session.getBasicRemote().sendText("This is the last server message"); } @OnOpen public void onOpen() { System.out.println("Client connected"); } @OnClose public void onClose() { System.out.println("Connection closed"); } }如何使用Encoder和Decoder传输更复杂的数据:Websocket使用Decoder将文本消息转换成Java对象,然后传给@OnMessage方法处理; 而当对象写入到session中时,Websocket将使用Encoder将Java对象转换成文本,再发送给客户端。
整个项目从简单的多线程优化到采用线程池来实现xml数据文件的获取
- 总体项目图
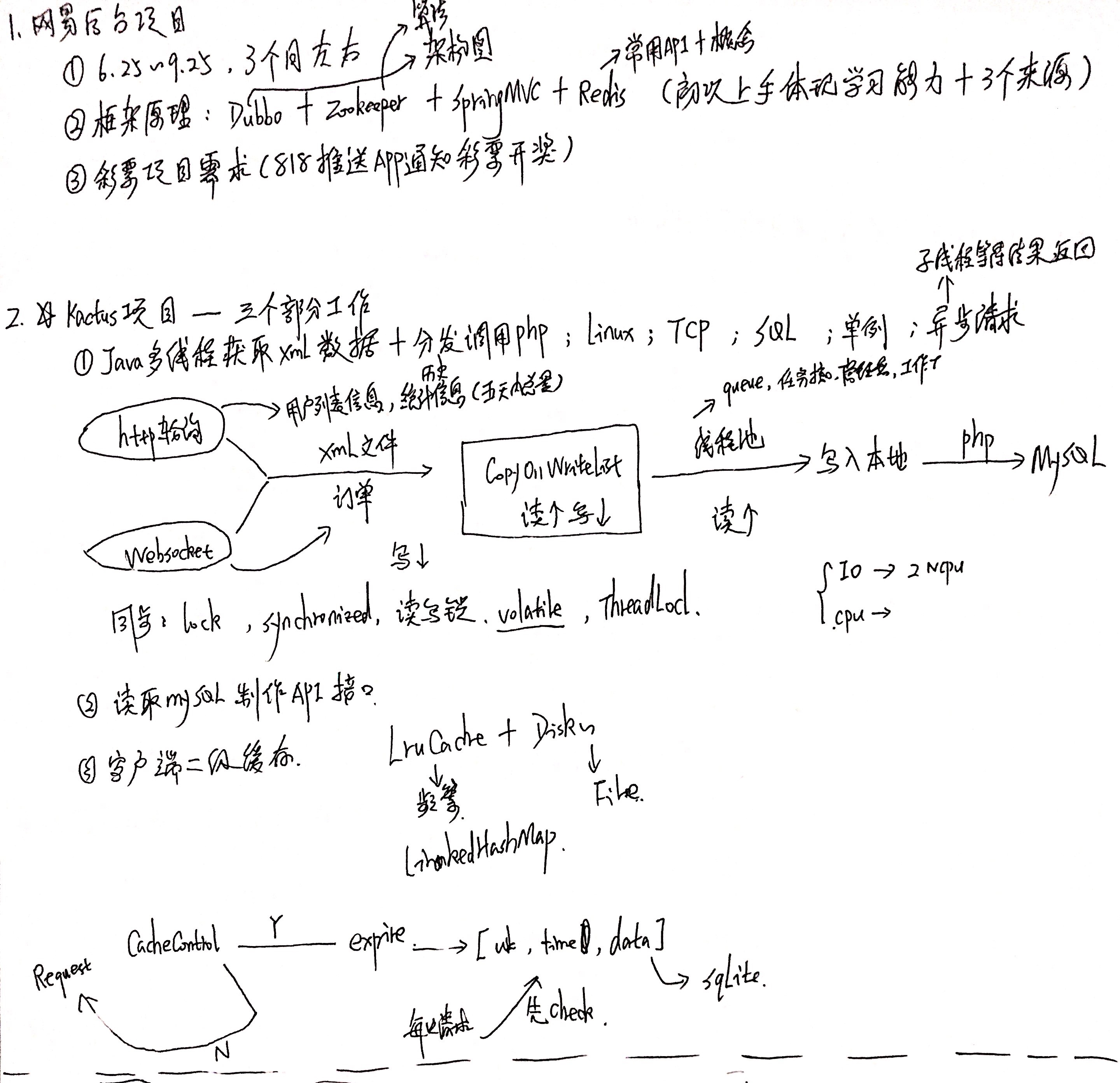
Baidu
Duwear项目短信管理模块: 目的是将手机短信库的变化情况通知到wear端
- SMSObserver继承ContentProvider类实现观察者模式,注册了一个短信数据库的观察者,发生变化该类都会被通知;在重载函数onChange中进行操作比对判断数据库变化情况,只知道变化,但是不知道具体操作?如何判断用户是标为已读还是删除,新建短信
- SmsReceivedListener接口:两个回调函数,作为一个接口参数传到SMSObserver的构造函数中,然后一旦判断是新短信还是短信已读,就调用其回调函数
- SmsRpcService类:继承自上边的接口,在回调函数中将这个操作判断出来发送给手表
- SmsUtils: 4个函数,查询短信数据库,标为已读的数据库操作函数
SMSObserver类中的具体的判断方式和优化过程
- 从维护所有信息的set到只维护未读信息的内容,信息实体占用内存很大,内存优化;
ArrayList到HashSet对比与区别:防止出现重复信息,去重速度很快因为使用HashTable中的hashCode()以及equals进行查找去重;
多次读取unreadSet并对两个set进行比对,removeAll和AddAll求补集并集来比对两个未读信息集合;两个方法都用到了hashCode和equals,所以SmsEntity对象中hashcode和equals方法的同时重载;直接removeAll新set可以判断出哪些信息被标为已读,AddAll新set再removeAll旧set可以判断得到新增加的短信;比如1,2,3和1,2,4,5
java集合中的浅复制和深复制,clone集合不影响原集合
浅复制: 复制后的对象与原对象所有变量的值相同,包括引用变量,浅复制时只会复制引用变量本身,不会复制它指向的对象本身
深复制: 复制后的对象与原对象所有变量的值相同,但是不包括引用变量,深复制时会复制引用变量指向的对象本身,所以引用值发生改变
Clone()方法和Cloneable接口: Cloneable接口是一个不包含方法的标志接口,一个类必须先继承它才能在其内部调用super.clone()方法,否则会抛出不支持clone的异常;clone()方法是一个native方法,拷贝对象时已经包括一部分原对象信息,效率优于使用新建对象再一一复制变量的方式;重写clone()方法需要先调用super.clone()方法,该方法会开辟一块新的内存用于拷贝原对象,将原对象的内容一一复制到新对象的内存空间中,它是一种浅复制;如果要实现深复制,需要对复制的对象中的所有引用变量对应的对象也进行复制(具体操作:重写引用对象的clone方法,在其中调用super.clone,然后在上层对象的重载clone方法中调用该对象的clone方法)
序列化实现深复制: 序列化主要用于将内存中对象状态写入数据库或者文件,以及利用Socket在网络中传输对象;一个对象要能够被序列化需要该类实现Serializable接口,可序列化类的子类默认也是可以被序列化的,不需要再次实现Serializable接口;利用序列化进行深复制的前提是该对象及其内部的引用到的对象都是可序列化的,这样对对象序列化时才能递归地保存对象及其引用对象的数据
deepClone() { //序列化:将内存中对象状态转化为字节流,写入目标输出流 ByteArrayOutoutStream bo=new ByteArrayOutputStream(); ObjectOutputStream oo=new ObjectOutputStream(bo); // oo.writeObject(this); //反序列化:读取源输入流中的字节流重建一个内存中相同状态的对象 ByteArrayInputStream bi=new ByteArrayInputStream(bo.toByteArray()); ObjectInputStream oi=new ObjectInputStream(bi); return(oi.readObject()); }当一个类声明要实现Serializable接口时,只是表明该类参加序列化协议;Java提供的ObjectInputStream和ObjectOutputStream将数据流功能扩展至可读写对象 。在ObjectInputStream中用readObject()方法可以直接读取一个对象,ObjectOutputStream中用writeObject()方法可以直接将对象保存到输出流中; 序列化只能保存对象的非静态成员变量,不能保存任何的成员方法和静态成员变量,而且序列化保存的只是变量的值,对于变量的任何修饰符都不能保存。
- 工厂模式生产手表View:需要生成许多不同的CardView,利用CardFactory中的BuildPage函数
- 简单工厂模式:工程类+抽象产品类+具体产品类;根据参数的不同返回不同类的实例。专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类
- 工厂方法模式: 抽象产品角色,具体产品角色,抽象工厂角色,具体工厂角色;工厂父类负责定义创建产品对象的公共接口,而工厂子类则负责生成具体的产品对象,这样做的目的是将产品类的实例化操作延迟到工厂子类中完成,即通过工厂子类来确定究竟应该实例化哪一个具体产品类;一个抽象产品类,可以派生出多个具体产品类。一个抽象工厂类,可以派生出多个具体工厂类。每个具体工厂类只能创建一个具体产品类的实例。
- 抽象工厂模式: 多个抽象产品类,每个抽象产品类可以派生出多个具体产品类。一个抽象工厂类,可以派生出多个具体工厂类。每个具体工厂类可以创建多个具体产品类的实例。
百度锁屏项目: View的自定义绘制与组合原理过程
网络通信的优化和实现过程http从同步的主线程发送get请求优化为异步的子线程发送post请求, 加强了数据传输的安全性和长度,解决了应用程序无响应的应用体验问题; httpClient和HttpUrlConnection的区别对比;最后学习和使用Volley以及OkHttp通信库
参考链接异步的get和post请求实现过程(HttpUrlConnection)
httpClient和httpUrlConnection, OKHttp对比:
- httpClient是apache的开源实现,API数量多,非常稳定
- httpUrlConnection是java自带的模块: ①可以直接支持GZIP压缩,而HttpClient虽然也支持GZIP,但要自己写代码处理 ②httpUrlConnection直接在系统层面做了缓存策略处理,加快重复请求的速度 ③API简单,体积较小,而且直接支持系统级连接池,即打开的连接不会直接关闭,在一段时间内所有程序可共用
- HttpURLConnection在Android2.2之前有个重大Bug,调用close()函数会影响连接池,导致连接复用失效,需要关闭keepAlive;因此在2.2之前http请求都是用httpClient,2.2之后则是使用HttpURLConnection
- 但是!!!现在!!!Android不再推荐这两种方式!二是直接使用OKHttp这种成熟方案!支持Android 2.3及其以上版本; 什么是OKHttp?
- Volley原理和OkHttp实现原理和应用方法以及优缺点
- Volley的调用过程,通过 newRequestQueue(…) 函数新建并启动一个请求队列RequestQueue后,只需要往这个RequestQueue不断 add Request 即可
- Volley:Volley 对外暴露的 API,通过 newRequestQueue(…) 函数新建并启动一个请求队列RequestQueue。
- Request:表示一个请求的抽象类。StringRequest、JsonRequest、ImageRequest 都是它的子类,表示某种类型的请求。
- RequestQueue:表示请求队列,里面包含一个CacheDispatcher(用于处理走缓存请求的调度线程)、NetworkDispatcher数组(用于处理走网络请求的调度线程),一个ResponseDelivery(返回结果分发接口),通过 start() 函数启动时会启动CacheDispatcher和NetworkDispatchers。
- HttpStack:处理 Http 请求,返回请求结果。目前 Volley 中有基于 HttpURLConnection 的HurlStack和 基于 Apache HttpClient 的HttpClientStack,也可以内部采用OKHttp实现
- CacheDispatcher.java:继承自Thread,用于调度处理「缓存请求」。启动后会不断从缓存请求队列中取请求处理,队列为空则等待,请求处理结束则将结果传递给ResponseDelivery去执行后续处理。当结果未缓存过、缓存失效或缓存需要刷新的情况下,该请求都需要重新进入NetworkDispatcher去调度处理。
- NetworkDispatcher.java:继承自Thread,用于调度处理「网络请求」。启动后会不断从网络请求队列中取请求处理,队列为空则等待,请求处理结束则将结果传递给ResponseDelivery去执行后续处理,并判断结果是否要进行缓存。
Volley与Activity生命周期联动与取消请求:为了在Activity退出或销毁的时候,取消对应的网络请求,避免网络请求在后台浪费资源;我们使用Volley的话,可以在Activity停止的时候,同时取消所有或部分未完成的网络请求,这些请求将不会被返回给主线程,取消操作一般在onStop()函数里边执行
// 遍历整个Activity中的请求集合,例如List for (Request <?> req : mRequestQueue) { req.cancel(); } // 取消整个队列中的请求 mRequestQueue.cancelAll(this); // 根据RequestFilter或者Tag来终止某些请求 mRequestQueue.cancelAll( new RequestFilter() {}); mRequestQueue.cancelAll(new Object());流程图解:
第一步:主线程根据优先级把请求加入缓存队列
第二步:「缓存调度线程」CacheDispatcher从缓存队列中取出一个请求,如果缓存命中,就读取缓存响应并解析,然后将结果返回到主线程
第三步:缓存未命中,该请求被加入网络请求队列,「网络调度线程」NetworkDispatcher(一个默认值为4的线程池)从网络队列中轮询取出请求,进行HTTP请求传输,解析响应,写入缓存,然后将结果返回到主线程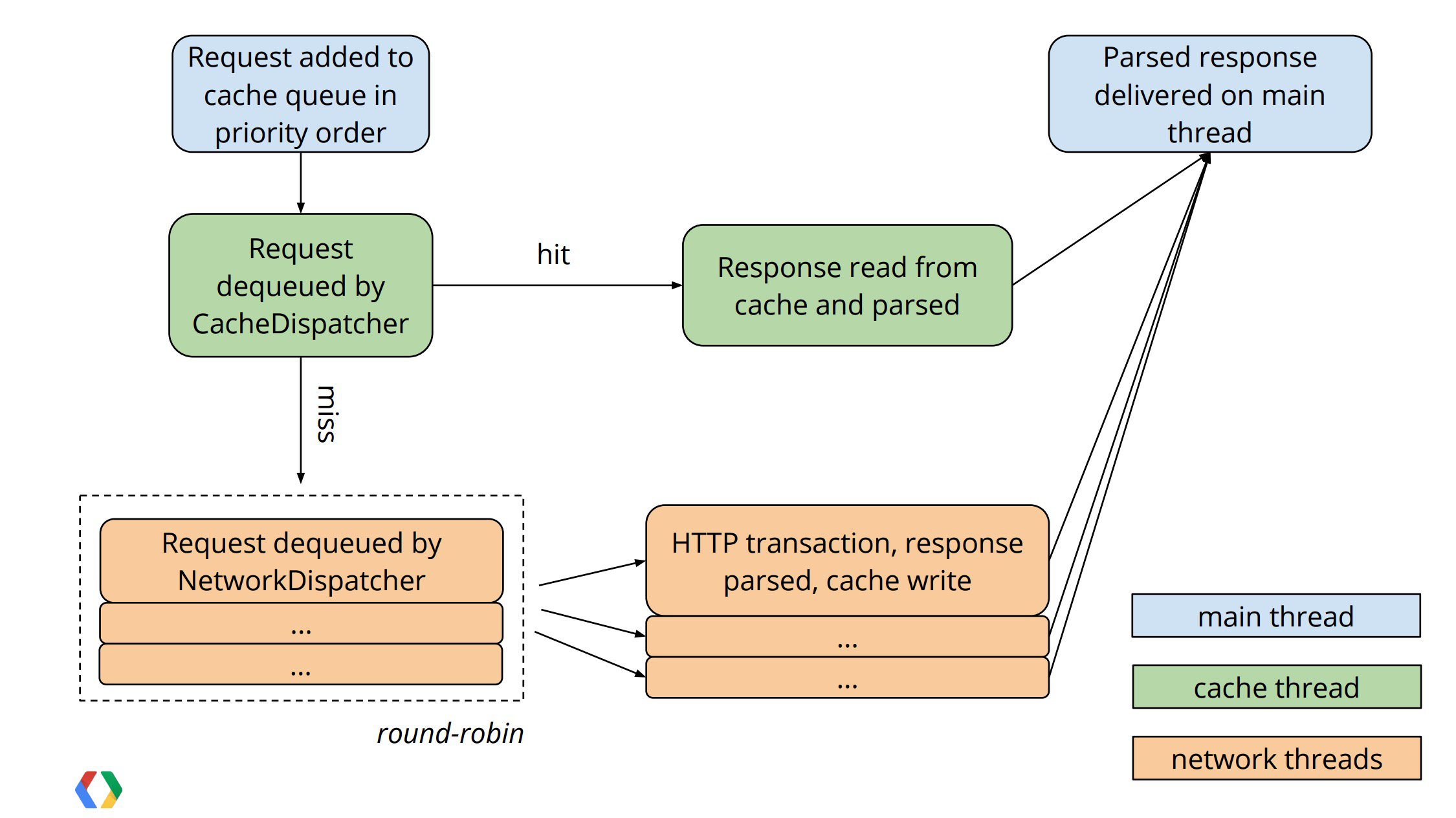
Volley用法
RequestQueue mQueue = Volley.newRequestQueue(context); StringRequest stringRequest = new StringRequest (Method.POST, "http://www.baidu.com", new Response.Listener<String>() { @Override public void onResponse(String response) { Log.d("TAG", response); } }, new Response.ErrorListener() { @Override public void onErrorResponse(VolleyError error) { Log.e("TAG", error.getMessage(), error); } }){ @Override protected Map<String, String> getParams() throws AuthFailureError { Map<String, String> map = new HashMap<String, String>(); map.put("params1", "value1"); map.put("params2", "value2"); return map; } }; mQueue.add(stringRequest);
OkHttp用法源码分析
OkHttpClient mOkHttpClient = new OkHttpClient();
FormEncodingBuilder builder = new FormEncodingBuilder();
builder.add("username","value");
Request request = new Request.Builder()
.url(url)
.post(builder.build())
.build();
mOkHttpClient.newCall(request).enqueue(new Callback(){
@Override
public void onFailure(Request request, IOException e)
{
}
@Override
public void onResponse(final Response response) throws IOException
{
//String htmlStr = response.body().string();
}
});
毕设-WebCrawler项目
java优先级队列;Java多线程处理,线程池,html页面解析等
单例模式enum实现对MySQL数据库操作的优势
开放性问题
- 说一个你曾独立或者作为核心去解决了的一个“有趣有难度”且过程很详细的步步深入优化的技术问题or项目
- 贡献和成果: 核心问题的效率优化过程与方法
- 困难:体现解决问题的方法与能力
- 思路:如果说有趣有难度的项目的话,我想说说kactus的食用油回收项目;在这个项目中参与时间长达半年,技术成长较大;这个项目主要是用来开发一个后台管理系统和Android app,包括司机和经理,用于订单处理和发布;在这个项目中,我参与了整个项目的研发,包括3个主要部分,①通过Java http和WebSocket请求订单数据,利用生产者消费者模式和多线程池提高并发读写效率 ②操作数据库制作RESTful API给移动端app使用 ③移动端app的开发以及二级缓存的优化实现
- 成就感最大的一件事: 比如学习,比赛,需要体现创新性的成果和idea:高德LBS的比赛全国八强,做了什么?为什么有成就感?从日常生活出发想出一个创新的idea,然后结合课程理论进行实践,到最后拿奖这样一个过程。
- 团队合作沟通能力和Team领导力
如何白板写代码???
- Show your idea,,例如白板写代码,遇到新问题即使不知道也可以开始分析,手动画图描述问题的解决过程,从思路到设计测试用例手动输入,一步步归纳出最终解法,转化成代码
- 解决问题的多角度性,从小问题和具体性问题开始入手,一步步递进归纳算法;遇到细节性或者较难实现的问题,可以先声明一个函数及其相应功能,留到后边再完善,代码效率的优化同样可以放到后边再做,思路的流畅性和清晰很重要。
- 主动单元测试,边缘情况测试,null,空字符串,StringUtils.isBlank(str)
遇到生活学习上的印象中最大的困难或者挫折?最后怎么解决的?
- 留学的DIY过程是一个比较困难的过程。为什么?绝大多数人会选择找中介,会省事很多,整个流程和材料的准备都不需要自己动手,但是我选择了自己DIY,所以在这一路的申请过程中遇到不少的挫折和困难,①对于留学的讯息了解不够 , ②准备考雅思 ③文书材料的撰写和修改;
- 最终这一路申请过程中虽然遇到各种困难,但是最终还是受益颇多,其实我本来自己DIY的原因就是我自己觉得申请过程其实是一次很好的审视自我的过程,也为我自己才是最了解我自己的人;不管结果如何,申请这个过程就是一段很好的人生经历,虽然遇到各种困难,但是一一克服,最终也有了一个比较好的结果,拿到了几家不错的offer
最大缺点: 这个问题好难回答啊!我想想……
* 我的缺点是比较专注和执着,比如在技术方面比较爱钻研,有的时候会为了研究一个技术问题,不断地沉浸在里边,不弄明白不罢休,到饭点了都能忘,晚上在公司研究到很晚才撤退。最近出的那个电脑端和手机端同步功能就很好,可以利用零碎时间看博客解决问题了 * 还有就是,工作比较按部就班,总是按照项目经管的要求完成任务。另外的缺点是,总在息的工作范围内有创新意识,并没有扩展给其他同事。这些问题我想我可以进入公司后以最短的时间来解决,我的学习能力很强,我相信可以很快融入公司的企业文化,进入工作状态。我想就这些吧。- 最大的特点或者优势:基础知识+创新能力
- 最感兴趣的课程 本科阶段的话,最感兴趣的是移动端开发,
- 最感兴趣的运动或者业余爱好,长期坚持的爱好: 羽毛球,吉他
- 性格特征
- 对感兴趣的技术会在业余时间去主动学习,刷刷coursera学习普林斯顿的算法课程学习常见算法堆排,买机器学习的书学KNN, 决策树 mapreduce相关知识
- 学习和做工程时愿意深入了解和钻研,多问为什么?例如做Kactus的回收油系统,从做移动端应用开发,我就会去考虑我拿的数据怎么来的,所以就会自己写程序去拿数据,拿到数据存到数据库,怎么做API把数据给移动端用,也自己做了,还会主动考虑着怎么去优化客户端体验,做二级缓存,怎么并行化收发数据来提高效率,怎么比较不同的http库去提高网络请求效率
- 能够发现生活细节,主动去发现问题,提出想法:比如高德项目,项目来源就是出去旅游发现人文景点不知道典故不好玩,看到有导游,怎么不用手机APP来做?,当时也有一些其他想法,比如运动分享记录APP
- 程序员中的外向者,善于与人交流沟通和参与社会活动从本科阶段的支教,社会调研等社会活动可以看出来
- 三个词形容自己:专注深入,发现问题(细心),淡定(有耐心的解决问题)
- 职业规划: :我希望从现在开始,1-2年之内能够在我目前的这个职位上沉淀下来,通过不断的努力后,最好能有晋升,希望3-5年内可以通过在现有的开发岗位上的不断学习和历练,基于现在的项目和平台,包括现在项目所提供的数据背景,条件,能够培养自己的大局观,逐步地从开发到架构,提升自己的业务水平
- 对比一下网易和百度的不同?整体的规范性,团队年轻,沟通非常顺利
- 这么多实习过程中最大的收获?①将理论和实践相结合的机会,了解到为什么学理论,并将学到的付诸于实践,做出真正可用的给成千上万的用户带去便利的产品,是件很有成就感的事情②大公司的开发规范和流程
- 为什么来北京?一方面是因为北京互联网工作机会多,类似于BAT之类的好公司好平台都在北京,是一个增长见识,锻炼自我的环境;二. 最优秀的人也在北京,在这样一个充满竞争的平台里,把握机会,成就自我。
- 你对薪资的要求?关于薪资的话,我个人倒是没有什么特别的要求,首先,我觉得公司提供的平台和成长更为重要,我会更加关注在这个良好的平台带来的自我能力的提升,这个才是比较长远的;另外,我也相信XX作为一家知名公司,在薪酬待遇上肯定不会差,而且校招也有一个合理的市场offer价格,如果公司对我的能力认同的话,肯定能协商出一个双方满意的offer待遇
- 如果公司录用你,你将怎样融入新团队开展工作?作为一个开发工程师而言,进入一个新的工作环境,参与一个新的产品项目我想我首先要积极融入团队,不管是生活上还是工作上,积极主动的沟通才能让我更快地了解整个团队,整个项目,多提问,多思考才能快速进步;然后要对部门的主营业务要有一个了解,了解公司的业务组成部分、业务的发展方向。第二了解我参与项目的开发方式,开发技术栈,架构方式,尽快投入具体的开发工作中。
- 加入新团队的挑战?你怎么融入???新的大模块的从无到有的项目接手的挑战;融入初期的担忧;技术的全局了解和深入快速学习;和团队人员之间的磨合,怎么磨合?
- 对公司的了解如何?希望获得什么?看中技术沉淀和业务前景;加班多么?压力大么?
Tips
- 面试时不要有“我记得 我认为 应该”,可以说我回想一下!一定要慢!声音大!有停顿!
- 不要说自己的工作简单!!!应该说自己快速高效完成,游刃有余,还能挤出时间自学;这是一个有难度的工作
- 压力面试时一定要淡定,即使不会也要有自信,有条不紊的回答问题,遭受质疑时要有理有据地说出自己的观点和自己知道的内容,并主动询问面试官的建议
- 记得问问题。
QA
如果在贵司移动开发部门做开发,主要是做哪些产品研发以及需要用到哪些技术知识和基础,我需要在哪些方面进行努力
面试过程中有没有什么地方讲得太快或者不清楚的地方,我可以补充的
如果可以,可否评价一下面试表现,提供一下您的建议和看法
跨平台应用研发,web轻应用和native app的开发前景比较看法
他们做什么业务,用些什么技术,希望面试者具备哪些方面的能力,对于做这个方向的人有什么建议,觉得我在技术上有什么优点和不足这种