何为Goroutine调度
Goroutine是Go语言原生支持并发的具体实现,所有代码都跑在goroutine里,我们可以启动许多goroutine,多个goroutine对应一个os thread,不过最多只能允许创建10000个os线程, 如果超过10000个会抛异常。
Goroutine调度就是决定何时哪个goroutine将获得资源开始执行、哪个goroutine应该停止执行让出资源、哪个goroutine应该被唤醒恢复执行等。
Goroutine调度器
传统语言中往往是代码负责创建线程,然后交给OS来进行线程调度。操作系统调度器会将系统中的多个线程or进程按照一定算法调度到物理CPU上去运行。这样会带来一些问题,例如
- 线程创建容易退出难,因为退出时要判断线程状态
- 并发单元间通信困难,易错,一旦涉及到shared memory,就会用到各种lock,死锁便成为家常便饭
- 相对于协程而言,线程开销依然很大,OS切换线程上下文的代价不小
在Golang中,goroutine可以认为是一种”轻量级线程” —- 协程,占用资源少。一个Go程序中可以创建成千上万个并发的goroutine,包括golang runtime在内的所有代码都跑在goroutine中,不涉及OS内核态。OS完全不知道goroutine的存在,go代码运行在一个或多个操作系统线程上。因此golang需要有调度器来负责调度这些goroutine,go scheduler负责将程序内的goroutines按照一定算法调度到不同的线程中去执行。
Go调度模型
G-M模型
Go 1.0版本的简单调度模型,G指代goroutine,对应于runtime中的一个抽象结构;M指machine,代表一个操作系统线程。该模型存在一些问题。例如单一全局互斥锁(Sched.Lock),意味着每个协程创建和调度都要加锁;M会做内存缓存,而且goroutine在M之间传递,造成调度延迟、、内存消耗、性能损耗。
G-P-M模型
1.1版本之后沿用至今的调度模型,内部采用work stealing算法。模型图如下:
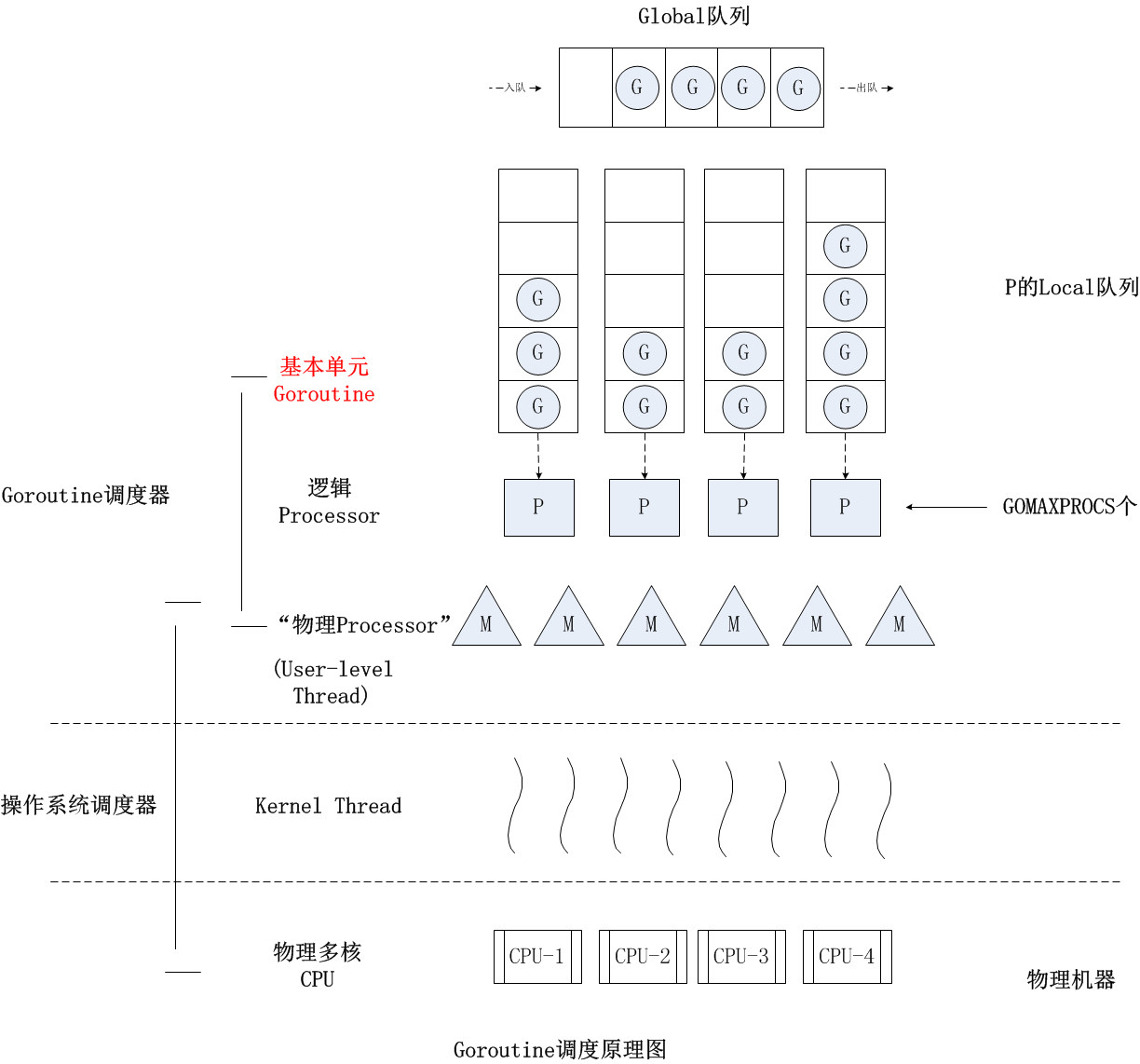
M represents an OS thread. It’s the thread of execution managed by the OS and works pretty much like your standard POSIX thread. In the runtime code, it’s called M for machine.
G represents a goroutine. It includes the stack, the instruction pointer and other information important for scheduling goroutines, like any channel it might be blocked on. In the runtime code, it’s called a G.
P represents a context for scheduling. You can look at it as a localized version of the scheduler which runs Go code on a single thread. It’s the important part that lets us go from a N:1 scheduler to a M:N scheduler. In the runtime code, it’s called P for processor.
- 可以看到G和M之间加了个中间层P—-逻辑Processor,对于G而言,它只与P打交道,多个G会被平均分配到多个P上执行,一旦一部分G被分派到某个P上边执行,它就会存在于P的本地队列中等待被执行;而P与M的关系,可以认为是每个P绑定唯一一个M的关系,启动时的P默认数目为系统物理处理器个数。
G-P-M调度机制
- 抢占式调度:
- 当一个G中出现死循环或永久循环的代码逻辑,那么G将永久占用分配给它的P和M,位于同一个P中的其他G将得不到调度,出现“饿死”的情况;因此Go 1.2实现了抢占式调度机制,在每个函数或方法的入口,加上一段额外的代码,让runtime有机会检查是否需要执行抢占调;然而对于没有函数调用,纯循环计算的G,无法抢占调度。Go的具体实现是启动一个sysmon的监控线程,不绑定P,每20us~10ms启动一次,向长时间运行的G任务发出抢占调度。
- 如果一个G任务运行10ms,sysmon就会认为其运行时间太久而发出抢占式调度的请求。一旦G的抢占标志位被设为true,那么待这个G下一次调用函数或方法时,runtime便可以将G抢占,并移出运行状态,放入P的local runq中,等待下一次被调度。
- 网络IO/channel阻塞调度:
- Go runtime通过实现netpoller机制来实现当goroutine发起网络I/O操作也不会导致M被阻塞(仅阻塞G),从而不会导致大量M被创建出来。
- 对于G被网络IO/channel阻塞,调度器会将当前G放入等待队列,等到阻塞操作完成之后再次被分配给某个P执行,而此时的M会去执行下一个runnable的G;如果此时没有runnable的G供M运行,那么M将解绑P,并进入sleep状态。
系统调用阻塞:
- 当G去执行一个文件IO类似的系统调用时会导致系统G和线程M都被阻塞,P就会与M分离,去寻找其他的idle的M,没有就去创建,从而可能导致大量创建新的M的问题
- Go 1.9增加了Poller for os package来实现在G操作支持pollable的fd时,仅阻塞G,而不阻塞M,不过对regular file无效
Tips:Go提供了调度器当前状态的查看方法, 使用Go运行时环境变量GODEBUG,例如
GODEBUG=schedtrace=1000 godoc -http=:6060
Go programs run with multiple threads, even when GOMAXPROCS is 1. The runtime uses goroutines that call syscalls, leaving threads behind.
In order to run goroutines, a thread must hold a context.
There are 3 usual models for threading. One is N:1 where several userspace threads are run on one OS thread. This has the advantage of being very quick to context switch but cannot take advantage of multi-core systems. Another is 1:1 where one thread of execution matches one OS thread. It takes advantage of all of the cores on the machine, but context switching is slow because it has to trap through the OS.
Go tries to get the best of both worlds by using a M:N scheduler. It schedules an arbitrary number of goroutines onto an arbitrary number of OS threads. You get quick context switches and you take advantage of all the cores in your system. The main disadvantage of this approach is the complexity it adds to the scheduler.
netpooler
当系统出现高并发的IO访问时,如一个网络服务器通常要并发处理成百上千的链接,每个链接可能都是由一个用户任务执行的,那么将会出现大量阻塞的IO操作,如果为每个阻塞操作都单独分配一个OS线程,那么将会增加系统的负载。因此在Golang中针对网络IO实现了netpooler来做特别的优化,只阻塞G,不阻塞M。
当goroutine读或写阻塞时会被放到等待队列,goroutine失去运行权,而M继续执行其它的G。后台的poller不停地poll,所有的文件描述符都被添加到了这个poller中,当某个时刻一个文件描述符准备好了,poller就会唤醒之前因它而阻塞的goroutine,于是goroutine重新被分配给某个P执行。
和使用Unix系统中的select或是poll方法不同地是,Golang的netpoller查询的是能被调度的goroutine而不是那些函数指针、包含了各种状态变量的struct等,这样你就不用管理这些状态,也不用重新检查函数指针等,这些都是你在传统Unix网络I/O需要操心的问题。