DFS和BFS
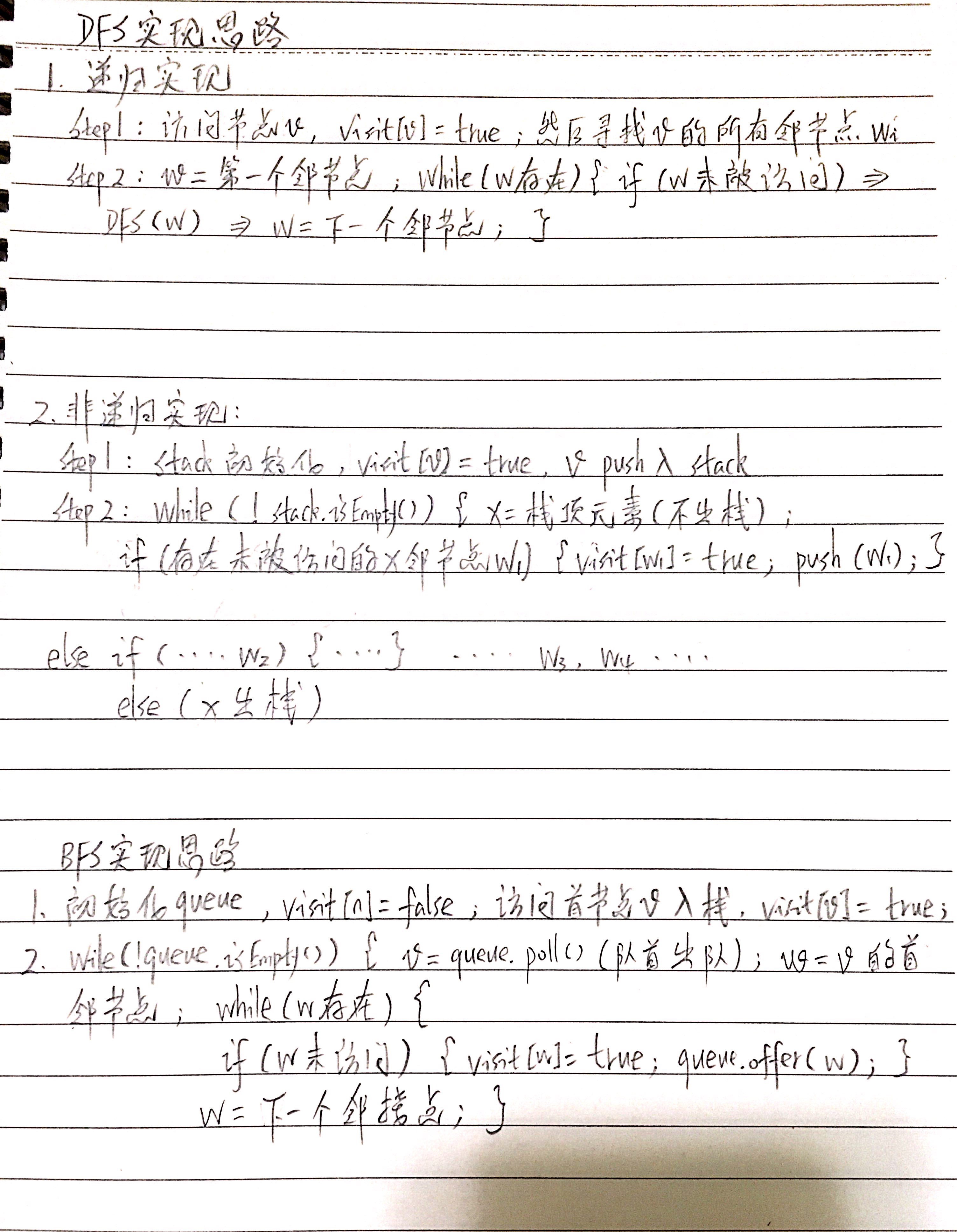
Tree
二叉查找树:(1)若左子树不空,则左子树上所有结点的值均小于它的根结点的值;(2)若右子树不空,则右子树上所有结点的值均大于它的根结点的值;(3)左、右子树也分别为二叉排序树;(4)没有键值相等的结点 (5) 特性就是”中序遍历“可以让结点有序.
- 范围查找是我们使用二叉树的最终目的,既然是范围查找,我们就知道了一个”min“和”max“,其实实现起来也很简单:
- 我们要在树中找到min元素,当然min元素可能不存在,但是我们可以找到min的上界,耗费时间为O(logn)
- 从min开始我们中序遍历寻找max的下界。耗费时间为m。m也就是匹配到的个数
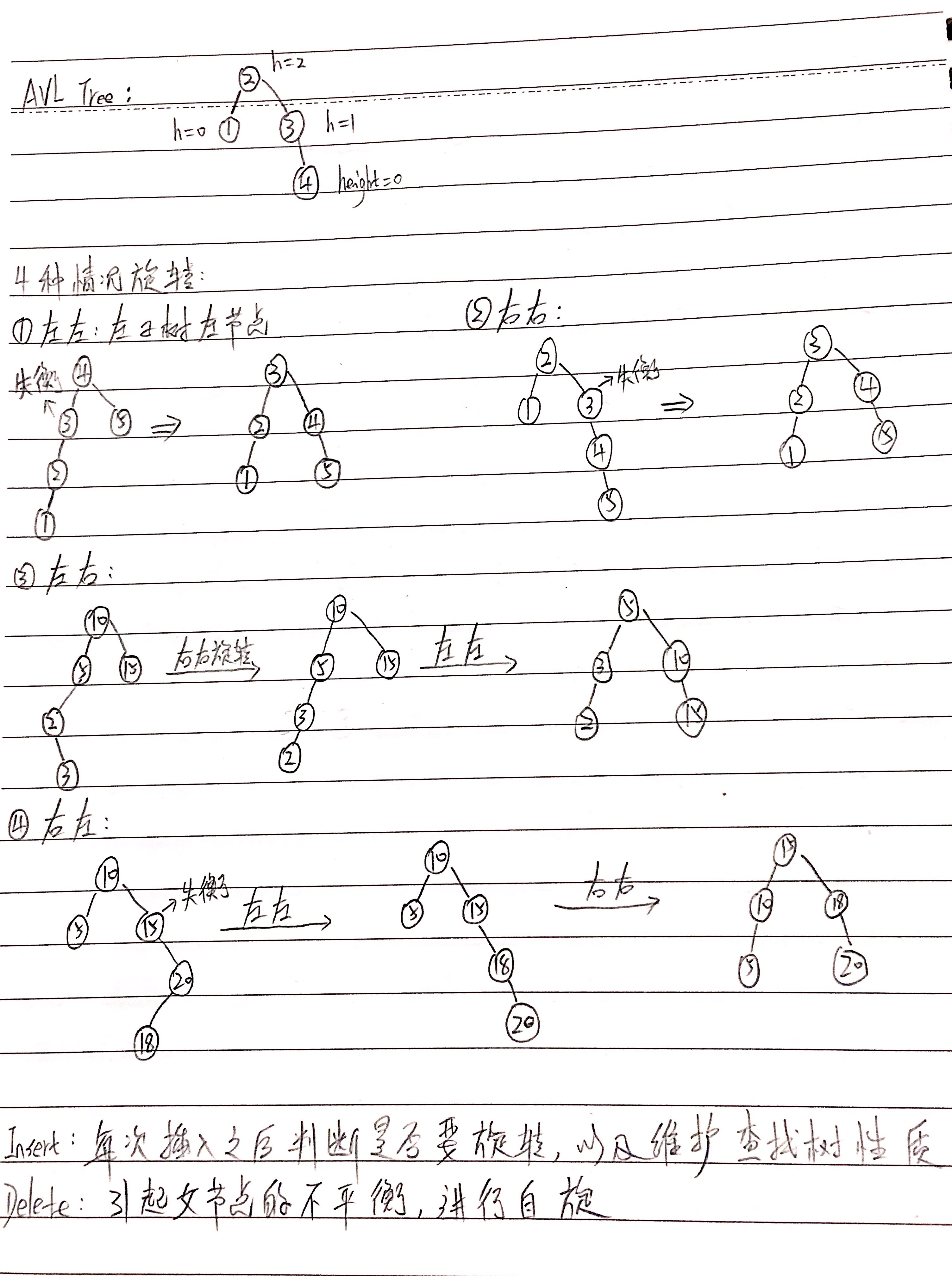
平衡二叉查找树(AVL): 父节点的左子树和右子树的高度之差不能大于1的二叉查找树,平衡之后能够保证查找,添加,删除的平均和最差时间复杂度都是严格的O(logN) Link
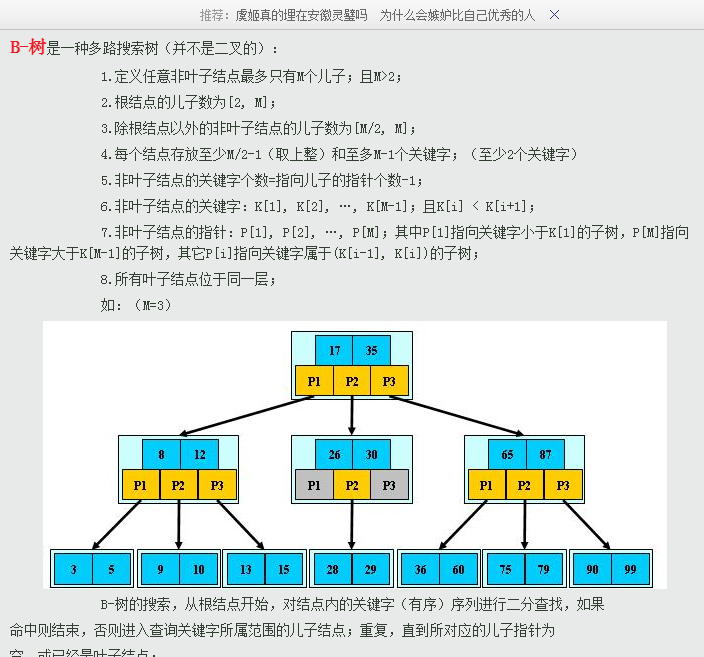
B-Tree:
- B+ Tree:一棵m阶的B+树和m阶的B树的异同点在于:
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。(而B 树的叶子节点并没有包括全部需要查找的信息)
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。(而B 树的非终节点也包含需要查找的有效信息)
- 为什么说B+树比B 树更适合实际应用中操作系统的文件索引和数据库索引?
- B+树的磁盘读写代价更低:B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
- B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
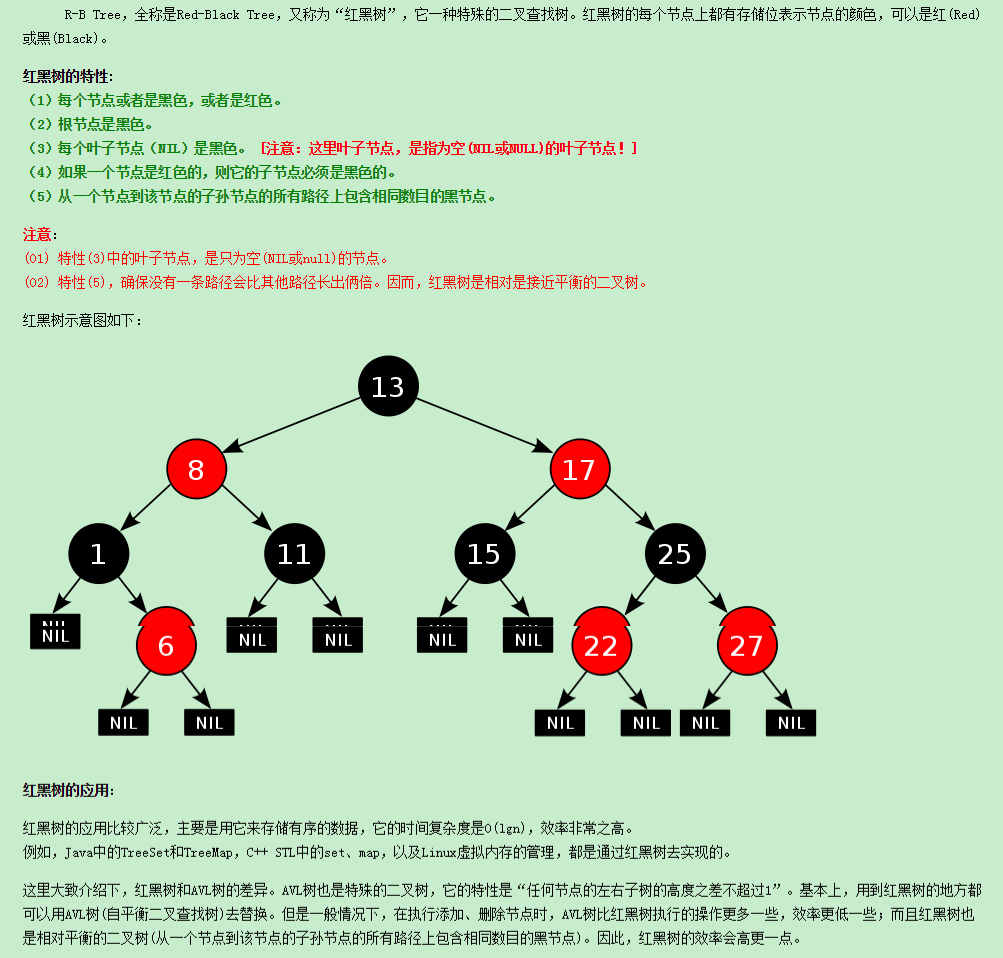
RB-Tree红黑树:
为什么MySQL数据库要用B+树存储索引?而不是B tree或者hashTable
KNN算法
- 基本思想: 从训练样本中找出K个与其最相近的样本,然后看这K个样本中哪个类别的样本多,则待判定的值(或说抽样)就属于这个类别
步骤:
- 计算已知类别数据集中每个点与当前点的距离;
- 选取与当前点距离最小的K个点;
- 统计前K个点中每个类别的样本出现的频率;
- 返回前K个点出现频率最高的类别作为当前点的预测分类
算法关键:Link
- 优缺点和应用场景
排序算法
插入与冒泡
快排
堆排
归并
o(n)的排序算法:基数排序+计数排序+通排序
桶排序
- 适用场景:待排序的元素能够均匀分布在某一个范围[MIN, MAX]之间
- 空间复杂度是O(n),因为需要额外的桶和桶内的元素链表空间;一种稳定的排序


