MVC模式是一种非常经典的复合型软件架构模式,它把用户界面交互分拆到不同的三种角色中,应用程序被分成三个核心部件:Model(模型)、View(视图)、Controller(控制器), 它们各自处理自己的任务,这样就可以把业务逻辑和视图显示解耦,提高了应用程序的灵活性和复用性。MVC模式不管是在web开发还是Android开发中都被广泛应用,最典型的MVC应用就是JSP + servlet + javabean的模式,例如SpringMVC开发框架。
Model模型:模型持有所有的数据、状态和程序逻辑,一个模型可以有不同的多个视图表现形式,复用性高。例如数据库记录以及相应增删查改操作;Android中对数据库的操作、网络请求、格式转换、文件下载、大数据处理等的耗时操作都在Model里面处理
View视图:视图是用户看到并与之交互的页面,通常直接从模型中取得它需要显示的状态与数据,一个视图往往有一个相应的控制器,理论上也可以同不同的模型相关联。例如html、xml页面;Android中主要是layout布局xml文件,webview等
Controller控制器:位于视图和模型中间,负责接受用户的输入,将输入进行解析并反馈给模型,例如Android开发中的Activity
MVC模式图解析:Event(事件)导致Controller改变Model或View,或者同时改变两者。只要Controller改变了Model的数据或者属性,所有依赖的View都会自动更新。类似的,只要Controller改变了View,View会从潜在的Model中获取数据来刷新自己。
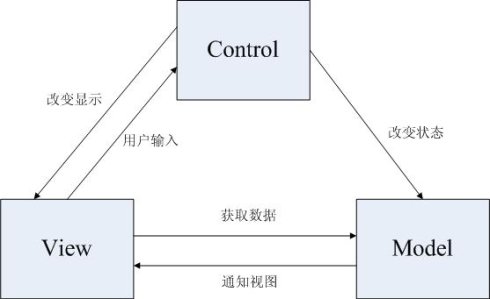
android中mvc的具体体现如下:
1)视图层(view):一般采用xml文件进行界面的描述,使用的时候可以非常方便的引入,当然,如何你对android了解的比较的多了话,就一定 可以想到在android中也可以使用javascript+html等的方式作为view层,当然这里需要进行java和javascript之间的通 信,幸运的是,android提供了它们之间非常方便的通信实现。
2)控制层(controller):android的控制层的重 任通常落在了众多的acitvity的肩上,这句话也就暗含了不要在acitivity中写代码,要通过activity交割model业务逻辑层处理, 这样做的另外一个原因是android中的acitivity的响应时间是5s,如果耗时的操作放在这里,程序就很容易被回收掉。
3)模型层(model):对数据库的操作、对网络等的操作都应该在model里面处理,当然对业务计算等操作也是必须放在的该层的。
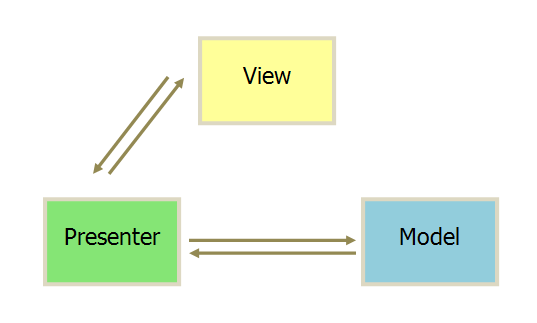
MVP模式
View不再与model交互,所有的交互通过presenter实现,双方之间的交互都是双向的,view层作为被动视图非常薄,没有任何的业务逻辑,业务逻辑都在presenter里边;Presenter与View的交互是通过接口来进行的