最近花了2天左右的时间看完了韩寒的这本书,总体感觉,嗯,很抽象的小说,却也有着很鲜明的现实意义,把社会现实和人性揭露得都很透彻,在此写写我读到了什么。
主人公貌似叫做路子野,而1988则是他的那辆由朋友帮忙改装好的旅游车,因为那辆车是1988年出厂,1988就是这么来的;他开着这辆车上路去接他的刚出狱的朋友,途中接受了已怀孕妓女娜娜的“特殊服务”却被警察查到,由此结缘,娜娜成为了他旅途的唯一伴侣;两个本来有着不同的目标、不同的社会经历和身份的人,在这个漫长的旅途中,他们互相交谈,聊着自己的人生经历,再加上这一路的经历,就组成了这么一本小说。
写到这儿,我想我是应该按小说中不同的事件来叙说感想,还是按照小说叙述的先后顺序来写呢?还是按照前者来写吧,应该会清楚一些。
常见设计模式实例讲解
单例模式的三种实现方式及其优缺点
public class SingletonDemo {
/**
* @param args
*/
public static void main(String[] args) {
SingletonEnum.INSTANCE.setmName("enum");
SingletonInner.getInstance().setmName("inner");
SingletonDoubleCheck.getInstance().setmName("doubleCheck");
}
/*
* 单例模式考虑点:
* 1. 线程安全:Synchronized关键字,Enum,静态内部类
* 2. 延迟加载:减少负载和消耗
* 3. 自动序列化(Serializable和transient)
* 4. 防止反射强行调用构造器
* 3、4点只有枚举可以实现
*/
/*
* 枚举实现单例
*/
public static enum SingletonEnum {
INSTANCE;
private String mName;
public String getmName() {
return mName;
}
public void setmName(String mName) {
this.mName = mName;
}
}
/*
* 双重检查锁:单例模式中需要new的情况非常少,第一层锁可以减少锁的次数
*/
public static class SingletonDoubleCheck {
private static volatile SingletonDoubleCheck singleton = null;
private SingletonDoubleCheck() {
}
public static SingletonDoubleCheck getInstance() {
if (singleton == null) {
synchronized (SingletonDoubleCheck.class) {
if (singleton == null) {
singleton = new SingletonDoubleCheck();
}
}
}
return singleton;
}
private String mName;
public String getmName() {
return mName;
}
public void setmName(String mName) {
this.mName = mName;
}
}
/*
* 内部类方式实现
*/
public static class SingletonInner {
private static class Holder {
private static SingletonInner singleton = new SingletonInner();
}
private SingletonInner() {
}
public static SingletonInner getInstance() {
return Holder.singleton;
}
private String mName;
public String getmName() {
return mName;
}
public void setmName(String mName) {
this.mName = mName;
}
}
}
工厂模式实例
观察者模式
- 在Java中通过Observable类和Observer接口实现了观察者模式,Observer对象监视着Observable对象的变化,当Observable对象发生变化时,Observer得到通知,就可以进行相应的工作。
- Observable类—-程序中的被观察者类需要继承这个类
- Observer接口—-观察者接口,观察者需要实现这个接口并重写其中的update()方法
- 可以在main函数中通过调用被观察者的addObserver方法添加观察者,当被观察者发生变化时要调用setChanged()方法标记此Observable对象已改变,并调用notifyObservers()通知所有观察者
自定义代码实现观察者模式:
// 被观察者接口 public interface Subject { public void registerObserver(Observer o); public void removeObserver(Observer o); public void notifyAllObservers(); } // 观察者接口 public interface Observer { public void update(Subject s); } // 猎头类 public class HeadHunter implements Subject { private ArrayList<Observer> userList; private ArrayList<String> jobs; public HeadHunter(){ userList = new ArrayList<Observer>(); jobs = new ArrayList<String>(); } @Override public void registerObserver(Observer o) { userList.add(o); } @Override public void removeObserver(Observer o) {} @Override public void notifyAllObservers() { for(Observer o: userList){ o.update(this); } } public void addJob(String job) { this.jobs.add(job); notifyAllObservers(); } public ArrayList<String> getJobs() { return jobs; } public String toString(){ return jobs.toString(); } } // 求职者类 public class JobSeeker implements Observer { private String name; public JobSeeker(String name){ this.name = name; } @Override public void update(Subject s) { System.out.println(this.name + " got notified!"); //print job list System.out.println(s); } } // 主函数 public class Main { public static void main(String[] args) { HeadHunter hh = new HeadHunter(); hh.registerObserver(new JobSeeker("Mike")); hh.registerObserver(new JobSeeker("Chris")); hh.registerObserver(new JobSeeker("Jeff")); //每次添加一个个job,所有找工作人都可以得到通知。 hh.addJob("Google Job"); hh.addJob("Yahoo Job"); } }
代理模式
- 代理模式就是为某个对象提供一个代理,以控制对这个对象的访问。 代理类和委托类有共同的父类或父接口,这样在任何使用委托类对象的地方都可以用代理对象替代。代理类负责请求的预处理、过滤、将请求分派给委托类处理、以及委托类执行完请求后的后续处理。
- 静态代理 由程序员创建或工具生成代理类的源码,再编译代理类。所谓静态也就是在程序运行前就已经存在代理类的字节码文件,代理类和委托类的关系在运行前就确定了。
- 动态代理 动态代理类的源码是在程序运行期间由JVM根据反射等机制动态的生成,所以不存在代理类的字节码文件。代理类和委托类的关系是在程序运行时确定。
- java.lang.reflect.Proxy :Java 动态代理机制生成的所有动态代理类的父类,它提供了一组静态方法来为一组接口动态地生成代理类及其对象, 其中newProxyInstance方法用于为指定类装载器、一组接口及调用处理器生成动态代理类实例
- java.lang.reflect.InvocationHandler:这是调用处理器接口,它自定义了一个 invoke 方法,用于集中处理在动态代理类对象上的方法调用,通常在该方法中实现对委托类的代理访问。每次生成动态代理类对象时都要指定一个对应的调用处理器对象。
适配器模式
- 适配器模式:将一个类的接口,转换成客户期望的另外一个接口。适配器让原本接口不兼容的类可以很好的合作;
两种方式:①类的适配器模式(采用继承实现)②对象适配器(采用对象组合方式实现); - 使用场景
- 系统需要使用现有的类,而这些类的接口不符合系统的接口。
- 想要建立一个可以重用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作
- 使用第三方组件,组件接口定义和自己定义的不同,不希望修改自己的接口,但是要使用第三方组件接口的功能。
装饰器模式VS代理模式
- 装饰器模式关注于在一个对象上动态的添加方法,是继承关系的一个替代方案;然而代理模式关注于控制对对象的访问,并不提供对象本身的增强功能。
- 对装饰器模式来说,装饰者和被装饰者都实现同一个接口; 对代理模式来说,代理类和真实处理的类都实现同一个接口
参考链接
- Java动态代理
数据库重难点集锦
常见的Hash算法和一致性哈希
线性哈希,平方取中法,随机数法,按位分割求和法
MD5和SHA这两种单向加密算法都是基于hash算法,前者产生128位的散列值,后者产生160位的散列值;两者都存在不同输入的散列值相同的情况,但是概率很低,为了防止被彩虹表破解,可以考虑加入Salt
Hash算法主要用于文件校验、数字签名、鉴权协议等
一致性哈希算法主要应用在cache系统中,常用的hash(object)%N算法会计算object 的hash值,然后对N取模得到余数i,该Object就会被映射到编号为i的cache上;那么当增加或者减少n的值时会导致所有的n个对象的映射全部发生改变,但是一致性哈希算法却只需要重新hash K/n个元素,为什么呢???; 因为一致性哈希的内部原理是将Object和cache都使用同一种hash算法hash到同一个数值空间上,该空间为一个首尾相接的圆环;然后如何将Object映射到cache呢?顺着顺时针方向,将每一个Object映射到下一个最邻近的cache,这样当新增一个cache时,只需要将原本映射到下一个cache上的Object部分映射修改到新增的cache上;当减少cache时就将之前映射到该cache的Object都映射到下一个cache上.
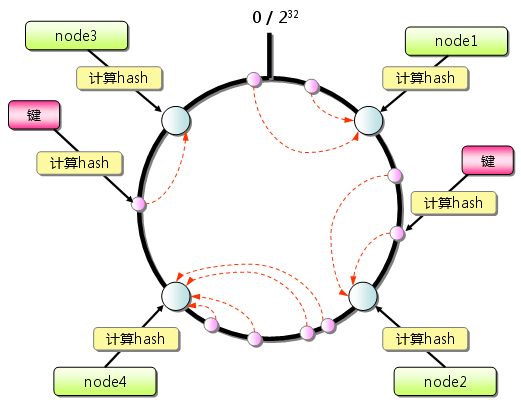
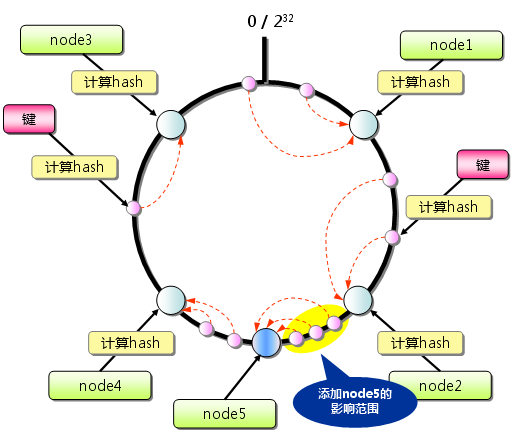
数据库结构概览

数据库的事务、索引、范式和存储过程概念以及优缺点
主键:数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)。
超键:在关系中能唯一标识元组的属性集称为关系模式的超键。一个属性可以为作为一个超键,多个属性组合在一起也可以作为一个超键。超键包含候选键和主键。
候选键:能够确定全部属性的某个属性或某组属性,称为候选键。若候选键多于一个,则选定其中一个作为主键
外键:在一个表中存在的另一个表的主键称此表的外键
事务:事务是数据库操作中的不可分割的逻辑单元,事务也是并发控制的基本单位,一个事务中的所有操作语句要么作为一个整体被执行,要么整体不被执行; 事务最重要的两个特性是事务的传播级别和数据隔离级别。传播级别定义的是事务的控制范围,事务隔离级别定义的是事务在数据库读写方面的控制范围。
- 原子性Atomicity:要么操作序列中全部语句都执行,要么全部不被执行,不可分割; 也就是说当事务的执行序列中某个语句执行错误,会回滚到该事务未执行时的状态
- 一致性Consistency:事务执行之后数据库从一个一致性状态转化到另一个一致性状态;数据库 ACID 中的一致性对事务的要求不止包含对数据完整性以及合法性的检查,还包含应用层面逻辑的正确。
- 隔离性Isolation:多个事务并行执行时互相之间不会影响
- 持久性Durability:事务成功执行之后会对数据库内容产生永久性影响,当事务已经被提交之后,就无法再次回滚了,唯一能够撤回已经提交的事务的方式就是创建一个相反的事务对原操作进行『补偿』
范式
- 第一范式:数据库表里边的每一列都是不可分割的原子性基本数据项
- 第二范式:数据库表里边每一个非关键字段都和任意一组候选关键字(主键)完全依赖,只有表的任意一组候选键有多个属性时才会出现部分依赖
- 第三范式:数据库里边每一个非关键字段都和主键直接相关,而不能是间接相关(传递依赖)
- BC范式:数据里边每一列既不部分依赖于任何候选键也不传递依赖于任何候选键;一个关系满足BCNF则一定满足第三范式
索引 :建立在数据库表的某些列上,例如需要搜索或者排序的列,主键列,外键列(用于连接的列),用在where语句中的列;有些列不应该建索引,比如:查询中很少使用或者参考的列, 只有很少数据值的列,定义为text, image和bit数据类型的列,当修改性能远远大于检索性能时,不应该创建索引;索引的实现通常使用B树及其变种B+树
- 参考: 一般来说,应该在这些列上创建索引:在经常需要搜索的列上,可以加快搜索的速度;在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
复合索引就是索引建立在多个列上,唯一索引就是保证索引列中的所有数据都是唯一的,不会存在冗余数据;聚集索引是指表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引
优点:
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
- 可以大大加快数据的检索速度
- 可以加速表和表之间的连接
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间
通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能
缺点:
- 创建索引和维护索引要耗费时间和大量的物理空间
- 对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度
存储过程
- 它是一组存储在数据库中的编译后的SQL语句集,可以接受参数以及返回值,也可以包括程序流,查询语句等
- 正常情况下,我们在code中写好SQL语句,连接数据库,SQL语句会被发送到服务器然后编译优化,数据库引擎执行编译后的查询语句,最后将查询结果返回给客户端;那么如果我们使用存储过程就可以省掉编译优化的过程,而且存储过程存储在database中,可以减少网络流量和传输时间;而且可以对存储过程授予制定权限,从而保证数据库操作安全
View
- 视图是一种通过自定义查询语句去查询筛选数据库表中的数据然后呈现给用户的一种动态生成的虚拟表,他和表一样包含行列数据,但是来自于其引用的表;其优点主要是可以保证数据库安全性以及筛选隐藏部分重要数据;View与Table之间的关系类似于MVC,在View中对数据进行修改会影响到Table中的数据,在Table中进行数据修改同样会显示到View,因为他们用的是同一份数据。
MySQL的隔离级别与锁
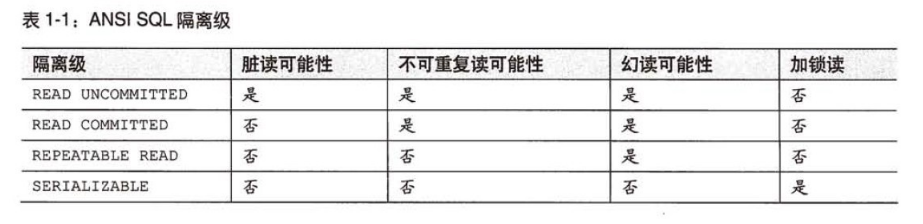
- 四种隔离级别: 隔离级别决定了一个会话中的事务可能对另一个会话的影响、并发会话对数据库的操作、一个会话中所见数据的一致性; MySQL的InnoDB支持四种隔离级别,默认是可重读隔离级别
- 未提交读READ UNCOMMITTED:最低级别的隔离,也被称之为脏读,它允许一个事务读取还没commit的事务的执行结果,这样可能会提高性能,但是导致脏读
- 提交读READ COMMITTED:在一个事务中只允许看见已经commit的事务所做的改变。如果一个session中select还在查询中,另一会话session此时insert一条记录,则新添加的数据不可见;只有该操作commit之后才可见,也就是说—-不可重复读
- 可重读REPEATABLE READ:同一个事务的多个实例在并发读取数据时会看到同样的数据行。也就是说在一个事务中重复select的结果一样,除非本事务中添加新数据到数据库,可能导致幻读;也就说事务之间只是在新数据方面突破了隔离,对已存在的数据仍旧隔离。
- 可串行化SERIALIZABLE:最高级别的隔离,强制事务排序并且只允许事务串行执行。为了达到此目的,数据库会锁住每个读的数据行,减少了并发,增加了稳定性,但是可能导致超时和锁竞争现象
- 事务并发导致的几个问题事务实现
- 脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个回滚了操作,则后一个事务所读取的数据就会是不正确的
- 不可重复读:在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新了原有的数据。
- 幻读:例如一个事务的两次查询过程中有另外一个事务插入数据造成第二次查询出现了在第一次查询中没有出现的数据;例如如果事务A运行”SELECT count(1) from TABLE_X” ,然后事务B在 TABLE_X 加入一条新数据并提交,当事务A再运行一次 count(1)结果不会是一样的,这就叫做幻读
- 隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed。它能够避免脏读取,而且具有较好的并发性能。尽管它会导致不可重复读和并发问题,可以由应用程序采用悲观锁或乐观锁来控制。
- 性质
- 共享锁:由读表操作加上的锁,加锁后其他用户只能获取该表或行的共享锁,不能获取排它锁,也就是说只能读不能写;一个事务获取了共享锁之后,可以对锁定范围内的数据执行读操作。
- 排它锁:由写表操作加上的锁,加锁后其他用户不能获取该表或行的任何锁;一个事务获取了排它锁之后,可以对锁定范围内的数据执行写操作。
- 乐观锁:读取数据时不锁,更新时检查是否数据已经被更新过,如果是则取消当前更新
一般在悲观锁的等待时间过长而不能接受时我们才会选择乐观锁;乐观锁适用于多读的应用类型,这样可以提高吞吐量- 乐观锁怎么实现和检查数据是否已经被更新???:
- ①使用数据版本记录机制实现也就是为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据
- ②在需要乐观锁控制的table中增加一个字段,字段名称无所谓,字段类型使用时间戳(timestamp), 和版本记录类似,也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则OK,否则就是版本冲突
- 悲观锁:在读取数据时锁住那几行,其他对这几行的更新需要等到悲观锁结束时才能继续;比如行锁,表锁等,读锁
- 表级锁:对整个表加锁,影响标准的所有记录;开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:对一行记录加锁,只影响一条记录;开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
- 锁管理器是添加和释放锁的进程,在内部使用一个哈希表来保存锁的相关信息(关键字是被锁的数据),并且了解每一块数据是被哪个事务加的锁,哪个事务在等待数据解锁;锁管理器还需要检查是否存在死锁,以及决定选择取消哪一个事务来消除死锁,检查死锁有两种方式一种是检查循环等待还有一种是使用超时设定。如果一个锁在超时时间内没有加上,那事务就进入了死锁状态。
- 数据库一般采用锁或者数据版本控制来进行并发控制 版本控制是每个事务可以在相同时刻修改相同的数据,每个事务有自己的数据拷贝(或者叫版本);如果2个事务修改相同的数据,只接受一个修改,另一个将被拒绝,相关的事务回滚(或重新运行);这将提高性能,因为:读事务不会阻塞写事务,写事务不会阻塞读,可以减少锁管理器带来的额外开销,但是磁盘空间消耗巨大,以空间换时间
- 乐观锁不会存在死锁的问题,但是由于更新后验证,所以当冲突频率和重试成本较高时更推荐使用悲观锁,而需要非常高的响应速度并且并发量非常大的时候使用乐观锁就能较好的解决问题,在这时使用悲观锁就可能出现严重的性能问题;在选择并发控制机制时,需要综合考虑上面的四个方面(冲突频率、重试成本、响应速度和并发量)进行选择。
- 共享锁(读锁):允许事务对一条行数据进行读取;互斥锁(写锁):允许事务对一条行数据进行删除或更新;
MySQL InnoDB实现
MyISAM和InnoDB存储引擎之间的区别
- InnoDB支持事务、外键和行锁,而MyISAM不支持这些高级功能,但是MyISAM是默认引擎,InnoDB则需要指定(事务是一种高级的处理方式,如在一些列增删改中只要哪个出错还可以回滚还原)
- MyISAM适合SELECT为主的应用,InnoDB适合频繁修改(INSERT或UPDATE)以及涉及到安全性较高的应用,因为InnoDB数据库在进行update时表进行行锁,并发量相对较大;而MyISAM在进行updata时进行表锁,并发量相对较小
- InnoDB不支持FULLTEXT类型的索引; 虽然InnoDB支持行锁,但是某些情况下还是锁整表,如 update table set a=1 where user like ‘%lee%’,因为该SQL语句不能确定要扫描的范围
- DELETE清空整个表时,InnoDB是一行一行的删除,效率非常慢。MyISAM则会重建表
- MyISAM的索引和数据是分开的,并且索引是有压缩的,内存使用率就对应提高了不少。能加载更多索引,而Innodb是索引和数据是紧密捆绑的,没有使用压缩从而会造成Innodb比MyISAM体积庞大不小
- InnoDB中不保存表的具体行数,也就是说,执行select count ( ) from table时,InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count() 语句包含where条件时,两种表的操作是一样的
- MyISAM缓存在内存的是索引,不是数据。而InnoDB缓存在内存的是数据
- MyISAM和InnoDB索引B+树结构的区别:MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址,索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。这种索引方式就属于“非聚集索引”;InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录
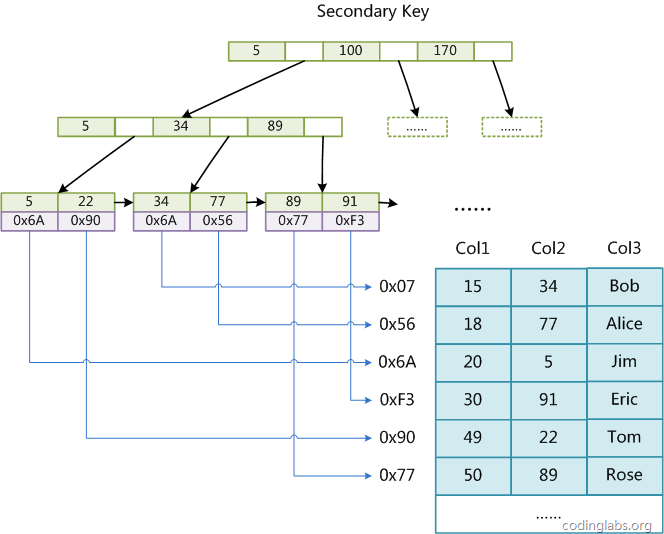
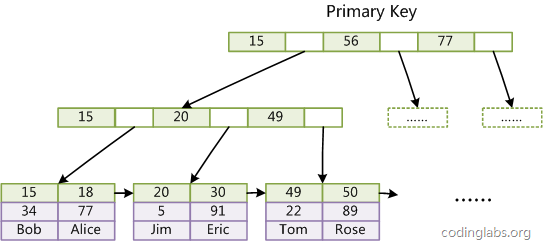
B+ Tree vs LSM 存储引擎的区别
关系数据库本质上是面向磁盘设计的,它把数据分成很多很多的页面,通过页面缓存机制来管理页面,底层的索引是B+树。这种引擎发展得非常成熟,但是写入性能差,原因是关系数据库的写入放大效应。用户数据是按行写入的,但是关系数据库却是按页面管理的,有时只写了一行数据,却不得不把整个页面刷入磁盘。另外一类流行的引擎是LSM树。例如LevelDB和RocksDB。这种引擎采用基线加增量的设计,数据首先以增量的形式写入到内存中,当增量达到一个阀值时统一写到磁盘。这种做法的好处是解决了关系数据库写入放大的问题,但是它的合并代价会比较大,可能出现合并速度赶不上内存写入的情况。
SQL语句
in和exists区别
- mysql中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询。一直大家都认为exists比in语句的效率要高,这种说法其实是不准确的,这个是要区分环境的。
- 效率对比:①如果查询的两个表大小相当,那么用in和exists差别不大;②如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in
- 实例(A<B):①select from A where cc in (select cc from B) 效率低,用到了A表上cc列的索引;②select from A where exists(select cc from B where cc=A.cc) 效率高,用到了B表上cc列的索引。③select from B where cc in (select cc from A) 效率高,用到了B表上cc列的索引;④select from B where exists(select cc from A where cc=B.cc) 效率低,用到了A表上cc列的索引。
not in和not exists区别
- not in 和not exists如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
- 在含有NULL值的列的时候,not in 逻辑上不完全等同于not exists;应该尽量不要使用not in(它会调用子查询),而尽量使用not exists(它会调用关联子查询)。如果not in子查询中返回的任意一条记录含有空值,则查询将不返回任何记录;因此除非子查询字段有非空限制,这时可以使用not in
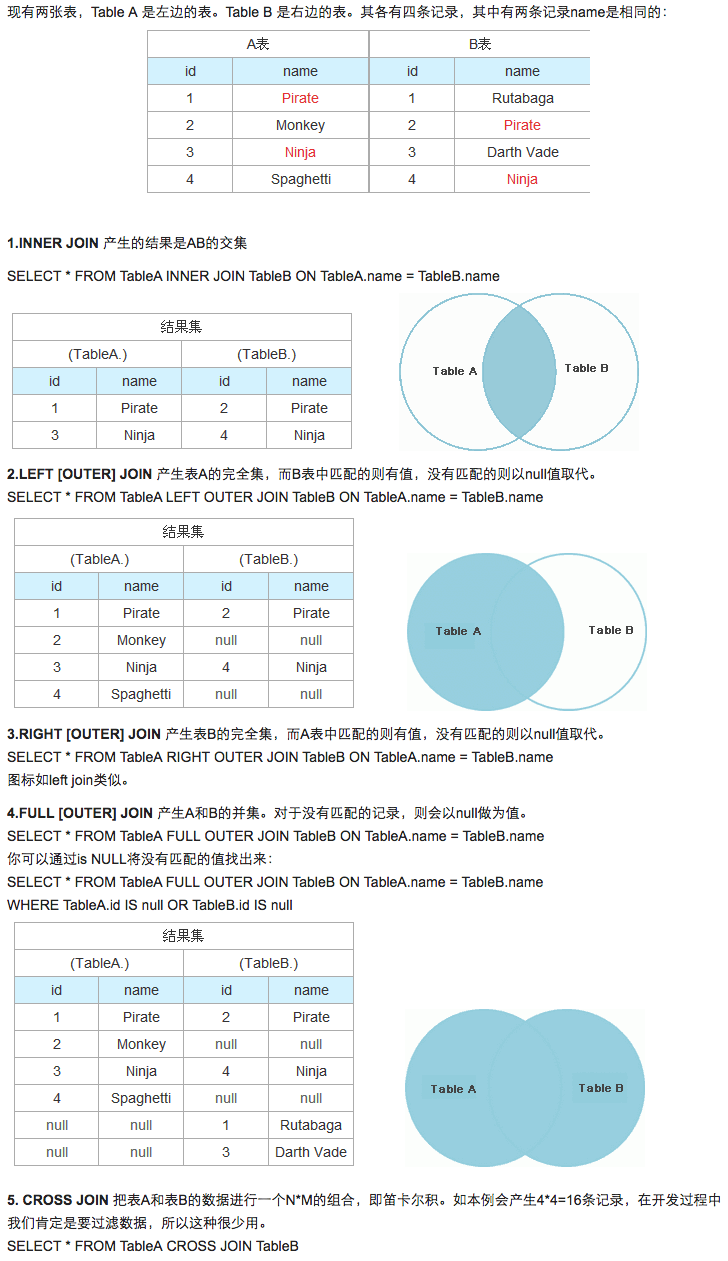
inner join、outer join和cross join的区别
日志管理器
- 为了提升性能,数据库把数据保存在内存缓冲区内。但如果当事务提交时服务器崩溃,崩溃时还在内存里的数据会丢失,这破坏了事务的持久性。你可以把所有数据都写在磁盘上,但是如果服务器崩溃,最终数据可能只有部分写入磁盘,这破坏了事务的原子性。因此我们采用事务日志是一个存储空间,在每次写盘之前,数据库在事务日志中写入一些信息,这样当事务崩溃或回滚,数据库知道如何移除或完成尚未完成的事务。事务的每一个操作(增/删/改)产生一条日志,
- MySQL中的两种日志,数据库恢复机制是通过回滚日志(undo log)或者重做日志(redo log)实现的;在数据库系统中,事务的原子性和持久性是由事务日志(transaction log)保证的,在实现时也就是上面提到的两种日志,前者用于对事务的影响进行撤销,后者在错误处理时对已经提交的事务进行重做,它们能保证两点:①发生错误或者需要回滚的事务能够成功回滚(原子性);②在事务提交后,数据没来得及写会磁盘就宕机时,在下次重新启动后能够成功恢复数据(持久性)
其它概念
- Transaction2 依赖于 Transaction1,而 Transaction3 又依赖于 Transaction1,当 Transaction1 由于执行出现问题发生回滚时,为了保证事务的原子性,就会将 Transaction2 和 Transaction3 中的工作全部回滚,这种情况也叫做级联回滚(Cascading Rollback),级联回滚的发生会导致大量的工作需要撤回,是我们难以接受的。
- 读写分离:
- Mysql有一个master-slave功能,可以实现主库与从库数据的自动同步,是基于二进制日志复制来实现的。
- 读写路由规则:编码使用不同数据源或者使用proxy层,MySQL-Proxy 是Mysql提供的一个中间件,用于实现读写分离请求,还有MyCat、ProxySQL 等
- CQRS:Command Query Responsibility Segregation:Command 主要做业务逻辑的执行,Query来负责数据查询和展示,两者可以来自不同的数据源
- 数据库sharding分片:
参考链接
Mac常用快捷键和Tips
在Mac系统中学会使用常用快捷键可以大大提高效率,以下为Mac系统中常用的快捷键和在Elipse开发中的常用快捷键(包含Mac和Win两个版本)。
Mac系统中常用快捷键
cmd+alt+1 --- 自动整理当前文件夹中文件
ctrl+space --- 启动spotlight全局搜索
cmd+space --- 切换输入法
cmd+向上/向下箭头 --- 返回上级文件夹/打开当前文件夹或文件
cmd+T --- 新建各种窗口(包括terminal窗口、finder窗口、chrome tab等)
cmd+shift+{/} --- 切换tab(包括finder、terminal等窗口tab)
cmd+shift+3 --- 屏幕截屏
cmd+shift+4 ---选取区域截图
cmd+delete --- 删除某个文件
enter --- 修改文件名(类似于win中的F2)
cmd+I --- 查看文件详细属性
cmd+option+esc --- 打开进程管理窗口
Mac常用设置方法
设置Eclipse中package explorer窗口中项目列表字体大小
Step1: 下载安装TinkerTool的软件
Step2: 点击fonts,修改Help tags的字体大小
Mac设置环境变量(adb+NDK+sdk)
无论是在windows还是mac系统下,对于程序猿而言,在terminal中输入命令进行一些常用操作是比用鼠标更为快捷的方式。那么为了能够打开terminal就可以直接输入并执行命令,就需要进行环境变量的设置,这样就不必进入命令文件所在目录下执行该命令了。windows下配置环境变量较为简单,在此讲一下mac下配置环境变量的方法和注意事项。
1. 打开terminal,输入cd ~, 进入当前用户home目录
2. 输入touch .bash_profile, 创建bash_profile文件(如果该文件已经存在则可以直接进入第3步)
3. 打开记事本编辑bash_profile文件,示例如下
方式一:用SDK_HOME指代一个通用路径,一处设置,多处使用,结构明晰,然后设置到PATH
export SDK_HOME=“/usr/sdk”
export PATH=${PATH}:${SDK_HOME}:${SDK_HOME}/tools:/usr/ndk
方式二:直接将各个命令的路径用:连接起来设置到PATH 形如--- export PATH=${PATH}:路径1:路径2:路径3
export PATH=${PATH}:/usr/sdk:/usr/sdk/tools:/usr/ndk
4. 保存修改,输入更新命令source .bash_profile,PATH变量配置完成