书籍使人进步!阅读使人明智!如何阅读一本书也是一门学问,读懂不同类型的书也是一件不容易的事情。美国教育家查尔斯-范多伦还特地写了一本《如何阅读一本书》来讲述读书的“方法论”,此文为部分书摘,闲来无事翻书,翻到哪儿写到哪儿,未完待续……
Java语言基础知识点
- Switch语句参数: JDK7之前,switch 只能支持 byte、short、char、int 这几个基本数据类型和其对应的封装类型;如果想用String,需要将String包装成枚举类型作为参数;JDK7之后支持String类型直接作为参数参考
- for循环和foreach的区别: for循环效率高于foreach; for循环可以间隔遍历,步伐可以自由设置,但是foreach只能用于遍历读取每一个元素,还不能进行修改
- Java和C++区别:①Java有接口,有垃圾回收机制②C++有引用,有多重继承,有操作符重载
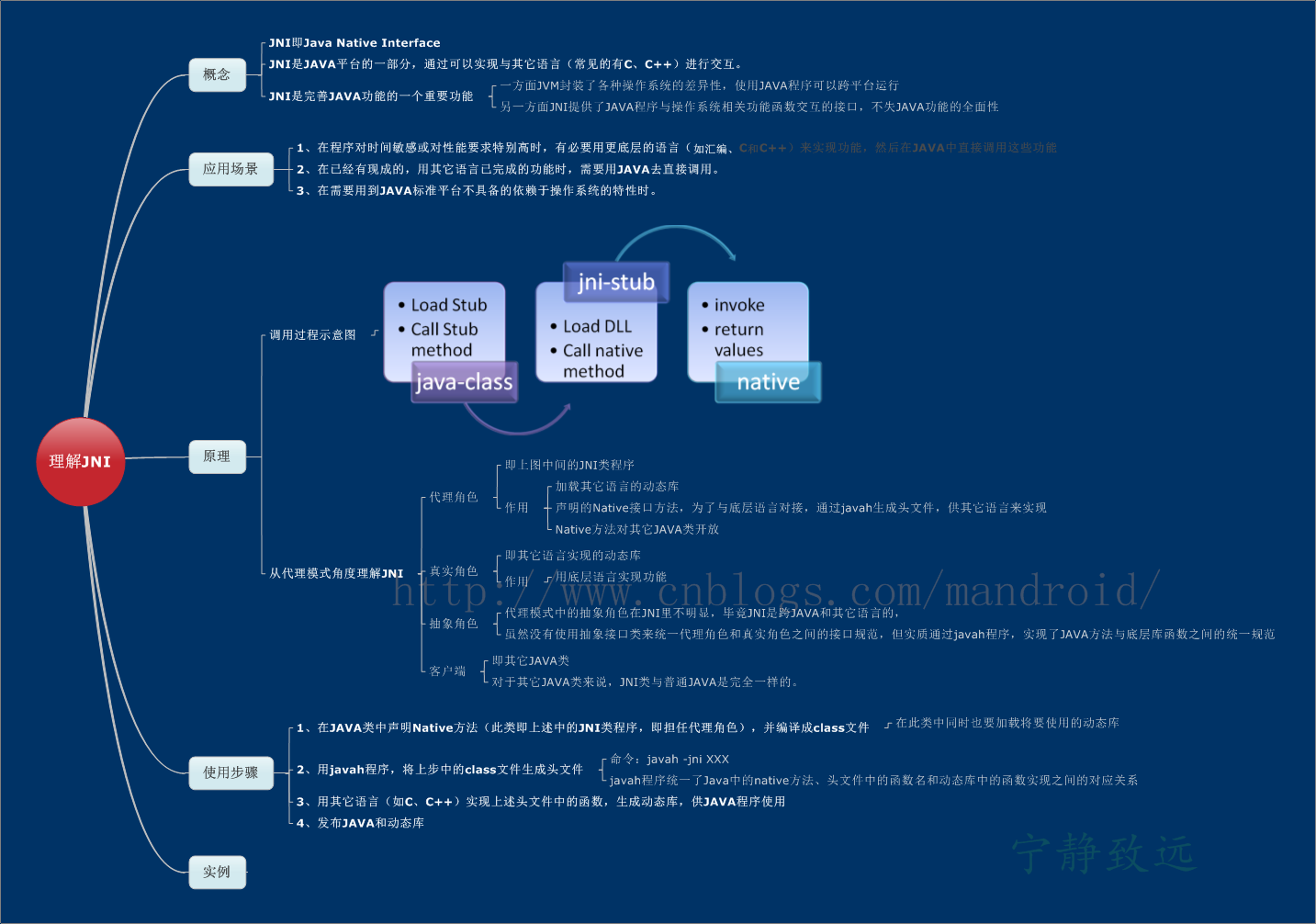
- JNI
- Java泛型:泛型是指在定义接口或者类时可以使用类型参数,泛型提供了编译期的类型安全检查,确保你只能把正确类型的对象放入集合中,避免了在运行时出现ClassCastException。Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节代码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会被编译器在编译的时候去掉,JVM看到的只是List,而由泛型附加的类型信息对JVM来说是不可见的。这个过程就称为类型擦除。比如一个方法如果接收List
BIO、NIO、AIO:三者之间的区别,类似于resin、apache、nginx在IO处理上的区别,从多线程互不干扰的阻塞式执行(resin),到轮询式的同步非阻塞式(apache),再到异步非阻塞式(nginx),现在这三种IO都在JDK中予以了支持
- BIO是面向流的同步阻塞式IO方式,对于每一个客户端Socket连接,服务端都会新开一个线程处理,在此期间线程一直被占用,直到socket关闭,其中tcp的连接、数据的读取read、数据的返回都是被阻塞的。也就是说这期间会大量的浪费cpu的时间片和线程占用的内存资源。优缺点和适应情景BIO方式具有很高的响应速度,并且控制起来简单,在连接数较少且固定的架构非常有效,但是如果对每一个连接都产生一个线程的无疑是对系统资源的一种浪费,如果连接数较多将会出现资源不足的情况。
- NIO(new IO从JDK1.4开始)是面向缓冲区的同步非阻塞式IO方式, 对于每一个客户端请求,服务端新开一个线程处理;即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理,当连接没有数据时,是没有工作线程来处理的; 它的非阻塞模式使用一个专用的reactor来处理分发IO事件,数据处理采用双通道模式,client和server各自维护一个选择器用于检测通道上的事件,通过访问选择器来处理感兴趣事件。优缺点和适应情景NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂
- AIO(Asynchronous IO从JDK1.7开始)是一种异步非阻塞的IO方式;对于每一个客户端的有效请求,服务端新开一个线程处理;即客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理,每个线程不必亲自处理IO,而是委派OS来处理,并且也不需要等待IO完成了,如果完成后,OS会通知的;优缺点和适应情景AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂
为什么匿名内部类和局部内部类只能访问final变量?:因为虽然匿名内部类在方法的内部,但实际编译的时候,内部类编译成Outer.Inner,这说明内部类所处的位置和外部类中的方法处在同一个等级上,外部类中的方法中的变量或参数只是方法的局部变量,这些变量或参数的作用域只在这个方法内部有效。因为编译的时候内部类和方法在同一级别上,所以方法中的变量或参数只有为final,内部类才可以引用,因为Java采用了一种copy local variable的方式来实现,也就是说把定义为final的局部变量拷贝过来用,而引用的也可以拿过来用,只是不能重新赋值。
- JDK8的新特性:
- 新增函数接口,引入注解@FunctionalInterface,函数式接口就是只有一个方法的普通接口
- 接口可以有默认方法和实现以及静态方法
- 取消方法区/永久代,采用元空间取代
- 新的Date-Time API
- 引入Optional类来防止空指针异常,它可以保存类型T的值,或者保存null。使用Optional类我们就不用显式进行空指针检查,主要是利用orElseGet(),flatMap()等函数
- Process类现在增加了两个新的方法用于终止进程;第一个是isAlive()方法,有了它你可以判断进程是否还活着。第二个方法则更加强大,它叫destroyForcibly(),你可以用它来强制的杀掉一个已经超时或者不再需要的进程
- Java8引入了一个新的读写锁StampedLock。它不仅更快,同时还提供了一系列强大的API来实现乐观锁,这样如果没有写操作在访问临界区域的话,你只需很低的开销就能获取到一个读锁。访问结束后你可以查询锁来判断这期间是否发生了写操作,如果有的话再选择进行重试,升级锁,或者放弃这个操作
- 新的增强的随机数生成方法SecureRandom.getinstanceStrong(),它能自动选择出当前JVM可用的最佳的随机数生成器。这样减少了获取失败的机率,同时也避免了默认的弱随机数生成器可能会导致密钥或者加密值容易被黑客攻破的问题
Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序;Stream 可以并行化遍历操作,使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出; Stream 的并行操作依赖于 Java7 中引入的 Fork/Join 框架(JSR166y)来拆分任务和加速处理过程
List<Integer> nums = Lists.newArrayList(1,null,3,4,null,6); // 创建stream --> map转换stream --> reduce聚合函数 // 含义:给定一个Integer类型的List,获取其对应的Stream对象,然后进行过滤掉null,再去重,再每个元素乘以2,再每个元素被消费的时候打印自身,在跳过前两个元素,最后取前四个元素进行加和运算 nums.stream().filter(num -> num != null). distinct().mapToInt(num -> num * 2). peek(System.out::println).skip(2).limit(4).sum();Java 8 中的 Lambda : 一段带有输入参数的可执行语句块,Lambda表达式取代了匿名类,取消了模板,允许用函数式风格编写代码。这样有时可读性更好,表达更清晰。书写形式:
(params) -> expression (params) -> statement (params) -> { statements }- 自动装箱就是Java自动将原始类型值转换成对应的对象,比如将int的变量转换成Integer对象,这个过程叫做装箱,反之将Integer对象转换成int类型值,这个过程叫做拆箱。自动装箱时编译器调用valueOf将原始类型值转换成对象,同时自动拆箱时,编译器通过调用类似intValue(),doubleValue()这类的方法将对象转换成原始类型值。原始类型byte,short,char,int,long,float,double和boolean对应的封装类为Byte,Short,Character,Integer,Long,Float,Double,Boolean。存在问题: ①自动装箱会隐式地创建对象,如果在一个循环体中,会创建无用的中间对象,这样会增加GC压力,拉低程序的性能 ② 缓存对象,在Java中,会对-128到127的Integer对象进行缓存,当创建新的Integer对象时,如果符合这个这个范围,并且已有存在的相同值的对象,则返回这个对象,否则创建新的Integer对象。
- JDK
参考链接
Java多线程同步方法
同步VS异步 and 阻塞VS非阻塞 Link
- 同步/异步与阻塞/非阻塞是两组不同的概念,它们可以共存组合,同步和异步与消息的通知机制有关,阻塞和非阻塞与程序等待消息(无所谓同步或者异步)时的状态有关 同步:就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回(与阻塞的区别很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已)。异步:当一个异步过程调用发出后,调用者不能立刻得到结果;这个调用的部件在处理完成后,通过状态、通知和回调来通知调用者。阻塞:是指调用结果返回之前,当前线程会被挂起,函数只有在得到结果之后才会返回。非阻塞指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。
- 举例: 我去买一本书,立即买到了,这就是非阻塞;如果恰好书店没有,我就等一直等到书店有了这本书买到了才走,这就是阻塞;这两种情况,非阻塞和阻塞都可以称为同步。如果书店恰好没有,我就告诉书店老板,书来了告诉我一声让我来取或者直接送到我家,然后我就走了,这就是异步。
Java对象锁和类锁
- 在Java程序运行时环境中,JVM需要对两类线程共享的数据进行协调:①保存在堆中的实例变量 ②保存在方法区中的类变量。
- 一个线程可以多次对同一个对象上锁。对于每一个对象,java虚拟机维护一个加锁计数器,线程每获得一次该对象,计数器就加1,每释放一次,计数器就减 1,当计数器值为0时,对象就被完全释放了。
- 对于同一个类A,线程1争夺A对象实例的对象锁,线程2争夺类A的类锁,这两者不存在竞争关系。也就说对象锁和类锁互补干预内政
互斥锁与读写锁
- 互斥锁:任意时刻,只能有一个线程持有锁。即假设A线程已经获取了锁,在A线程释放这个锁之前,B线程是无法获取到这个锁的,B要获取这个锁就会进入阻塞状态。例如synchronized和ReentrantLock都属于互斥锁
- 读写锁ReadWriteLock:Java并发包中实现ReadWriteLock接口的ReentrantReadWriteLock,它并没有实现Lock接口,是其内部类ReadLock和WriteLock实现了Lock的接口
- 在真实的业务场景中,通常会出现对一份数据的读取操作次数远高于写入操作这种读多写少的场景,而线程与线程间的读读操作是不涉及到线程安全的问题,没有必要加入互斥锁
- 所以读写锁只要满足“读-读”不互斥 ,”读-写”互斥 ,”写-写”互斥;也就是说只要在任何时候必须保证:①只有一个线程在写入;②线程正在读取的时候,写入操作等待;③线程正在写入的时候,其他线程的写入操作和读取操作都要等待;这样,使用读写锁就可以大大提高效率
- 读写锁实例讲解
Synchronized代码块和方法
- synchronized关键字强制实施一个互斥锁,使得被保护的代码块在同一时间只能有一个线程进入并执行,用于防止多线程访问临界共享资源出现数据不一致性;但是同步是一种高开销的操作(因为在锁竞争激烈的情况下,各个线程不断在阻塞和运行状态之间切换会导致操作系统的上下文切换开销非常大),因此应该尽量减少同步的内容;通常没有必要同步整个方法,使用synchronized代码块同步关键代码;
Synchronized锁住的是对象或者类,对象被锁住时,该对象所有的其他同步方法和代码块不能被执行;类被锁住时,该类所有的其他同步静态方法和代码块不能被执行
class Bank { private int account = 100; public int getAccount() { return account; } /** * 用同步方法实现 * * @param money */ public synchronized void save(int money) { account += money; } /** * 用同步代码块实现 * * @param money */ public void save1(int money) { synchronized (this) { account += money; } } }
ReentrantLock可重入锁
- 可重入锁,也叫做递归锁,指的是同一线程外层函数获得锁之后,内层递归函数仍然有获取该锁的代码,但不受影响;即被同一个线程多次获取,而不会产生死锁。在JAVA环境下 ReentrantLock 和synchronized 都是可重入锁
- ReentrantLock是可重入、互斥、实现了Lock接口的锁,需要自己手动加锁与释放;要注意及时释放锁,否则会出现死锁,通常在finally代码释放锁;它能完成Synchronized所实现的所有功能,而且性能上有一定提升
- ReentrantLock的常用方法:
- lock(), 如果获取了锁立即返回,如果别的线程持有锁,当前线程则一直处于休眠状态,直到获取锁
- lockInterruptibly -> 调用后一直阻塞到获得锁(和lock()一样),但是接受中断信号
- tryLock(), 如果获取了锁立即返回true,如果别的线程正持有锁,立即返回false
- tryLock(long timeout,TimeUnit unit),如果获取了锁定立即返回true,如果别的线程正持有锁,会等待参数给定的时间,在等待的过程中,如果获取了锁定,就返回true,如果等待超时,返回false
- synchronized和ReentrantLock的主要区别
- ReentrantLock新特性
- 等待可中断—-在持有锁的线程长时间不释放锁的时候,等待的线程可以选择放弃等待. 使用tryLock(long timeout, TimeUnit unit)方法
- 公平锁(按照申请锁的顺序来依次获得锁称为公平锁)—-synchronized的是非公平锁,ReentrantLock可以通过构造函数实现公平锁. new RenentrantLock(boolean fair)
- 可绑定多个Condition—-通过多次newCondition可以获得多个Condition对象,可以简单的通过await(),signal()方法实现比较复杂的线程同步的功能
- 使用场景并发量比较小的情况下,Synchronized的性能要优于ReetrantLock,但是在并发量比较高,资源竞争很激烈的情况下,其性能下降很严重,此时ReentrantLock是个不错的方案;如果synchronized关键字能满足用户的需求,就用synchronized,因为它能简化代码,可读性高,而且编译器会尽可能优化synchronize
- ReentrantLock新特性
class Bank {
private int account = 100;
// 创建一个ReentrantLock锁
private Lock lock = new ReentrantLock();
public int getAccount() {
return account;
}
public void save(int money) {
lock.lock(); // 获得锁
try {
account += money;
} finally {
lock.unlock(); // 释放锁
}
}
}
自旋锁
- 自旋锁是对线程阻塞的一种优化,他的原理是当线程争用锁失败的时候不立即进入阻塞状态,而是再等一会,因为对于执行时间短的代码这一会可能就会释放锁,而线程就不需要进行一次阻塞与唤醒。这个等待操作就是让线程多执行几个空指令,至于等待多久这跟具体的处理器实现有关,也有可能处理器根本不支持自旋锁,具体实现的时候我们可以设置一个临界值,当超过了这个临界值之后我们就不自旋了,就乖乖进入阻塞状态吧。这种优化对于执行时间短的代码是很有效的。synchronized使用自旋锁的时机是线程进入等待队列即阻塞的前一步。
- 无锁例如Disruptor并发框架,Disruptor底层依赖一个RingBuffer来进行线程之间的数据交换,在并发条件下,多线程对RingBuffer的读和写不会涉及到锁,然而因为RingBuffer满或者RingBuffer中没有可消费内容引发的线程等待,那就要另当别论了。Disruptor无锁原理RingBuffer维护者可读和可写的指针,也叫游标,它指向生产者或消费者需要写或读的位置,而对于指针的更新是由CAS来完成的,这个过程中我们不需要加锁/解锁的过程。
ThreadLocal线程局部变量
- ThreadLocal与同步机制区别:a.ThreadLocal与同步机制都是为了解决多线程中相同变量的访问冲突问题。b.前者采用以”空间换时间”的方法,后者采用以”时间换空间”的方式
- 性质每一个使用ThreadLocal变量的线程都获得该变量的副本,副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响
- 四个函数:initialValue函数用于获取此线程局部变量的初始值;get用于获取此线程局部变量在当前线程中的副本值,set用于设置,remove用于移除此线程局部变量在当前线程中的副本值;顺序在进行get之前,必须先set,否则会报空指针异常;如果想在get之前不需要调用set就能正常访问的话,必须重写initialValue()方法
实现原理:内部持有一个叫做ThreadLocalMap的内部类,从源码可以看出这个ThreadLocalMap的Entry继承了WeakReference,并且使用ThreadLocal作为键值,以键值对形式存储着[ThreadLocal对象, 存放的值],每个线程中可有多个threadLocal变量
public class Bank { // 使用ThreadLocal类管理共享变量account private ThreadLocal<Integer> account = new ThreadLocal<Integer>() { @Override protected Integer initialValue() { return 100; } }; public void save(int money) { account.set(account.get() + money); } public int getAccount() { return account.get(); } }
volatile变量可见性
volatile: 在需要同步的变量上加上修饰符volatile,例如:private volatile int account = 100;volatile可以保证变量的可见性但是不保证原子性,不能用于修饰final常量,线程每一次对volatile变量的修改都会即时刷新到主存和通知到其他线程,也就是说每一次每个线程读取volatile变量时都会从主存中去取而不会从缓存寄存器中获取,以确保变量的值都是最新获取的;该关键字在JDK1.6开始可以保证指令不被重排序;但是他不能保证原子性,比如n++这种复合型操作;java虚拟机规范(jvm spec)中,规定了声明为volatile的long和double变量的get和set操作是原子的,所以将long和double类型的变量用volatile修饰,就可以保证对他们的赋值操作的原子性。适用场景:作为状态标识量适用,也在双重检查的单例中使用;适用于一个线程写,多个线程读的情况;两个条件:①对线程的写操作不依赖于当前值 ② 该变量没有包含在具有其他变量的不等式中
CAS比较并交换操作:CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B). CAS有效地说明了“我认为位置 V 应该包含值 A;如果包含该值,则更新值为B;否则,不要更改该位置,只告诉我这个位置现在的值即可。” 处理ABA情况,引入[引用, 版本号]机制来确保ABA也说明该数据已经被其他线程修改过
例如,有一个变量i=0,Thread-1和Thread-2都对这个变量执行自增操作。 可能会出现Thread-1与Thread-2同时读取i=0到各自的工作内存中,然后各自执行+1,最后将结果赋予i。这样,虽然两个线程都对i执行了自增操作,但是最后i的值为1,而不是2。
解决这个问题使用互斥锁自然可以。但是也可以使用CAS来实现,思路如下:
自增操作可以分为三步:(1)从内存中读取这个变量的当前值(2)执行(变量=上一步取到的当前值+1)的赋值操作 (3)将自增后的值写入变量
多线程情况下,自增操作出现问题的原因就是执行(2)的时候,变量在主内存中的值已经不等于上一步取到的当前值了,所以赋值时,用CompareAndSet操作代替Set操作:首先比较一下内存中这个变量的值是否等于上一步取到的当前值,如果等于,则说明可以执行+1运算,并赋值;如果不等于,则说明有其他线程在此期间更改了主内存中此变量的值,上一步取出的当前值已经失效,此时,不再执行+1运算及后续的赋值操作,而是返回主内存中此变量的最新值。“比较并交换(compare_and_swap)”操作是原子操作,它使用平台提供的CPU级别上的用于并发操作的硬件原语。
原子(atom)本意是“不能被进一步分割的最小粒子”,而原子操作(atomic operation)意为”不可被中断的一个或一系列操作”
基于CAS的并发算法称为“无锁定算法”,因为线程不必再等待锁定。“无锁定算法”要求某个线程总是执行操作
Wait && Notify同步(生产者消费者模式实现)
- Wait调用任意对象的wait()方法导致该线程阻塞,并释放该对象上的锁,进入等待对象同步锁的状态;Notify随机唤醒一个等待对象同步锁的线程
- wait()方法:当缓冲区已满/空时,生产者/消费者线程停止自己的执行,放弃锁,使自己处于等待状态,让其他线程执行。notify()方法:当生产者/消费者向缓冲区放入/取出一个产品时,向其他等待的线程发出可执行的通知,同时放弃锁,使自己处于等待状态。
- 生产者-消费者(producer-consumer)问题,也称作有界缓冲区(bounded-buffer)问题,两个进程共享一个公共的固定大小的缓冲区。其中一个是生产者,用于将消息放入缓冲区;另外一个是消费者,用于从缓冲区中取出消息。问题出现在当缓冲区已经满了,而此时生产者还想向其中放入一个新的数据项的情形,其解决方法是让生产者此时进行休眠,等待消费者从缓冲区中取走了一个或者多个数据后再去唤醒它。同样地,当缓冲区已经空了,而消费者还想去取消息,此时也可以让消费者进行休眠,等待生产者放入一个或者多个数据时再唤醒它
- 如何停止消费者: 第一种方法: 设置一个Volatile的boolean类型变量作为flag, 生产者结束后标示该变量为true, 消费者轮询这个变量来决定自己是否退出; 第二种方法: 经典的“毒丸”策略,生产者结束后,把一个特别的对象:“毒丸”对象放入队列。消费者从队列中拿到对象后,判断是否是毒丸对象。如果是普通非毒丸对象,则正常消费。如果是毒丸对象,则放回队列(并杀死其他消费者),然后结束自己。
- 代码实现:
public class ProducerCustomer {
/**
* @param args
*/
public static void main(String[] args) {
Product product = new Product(); // 实例化产品对象
Producer p = new Producer(product); // 实例化一个生产者
Consumer c = new Consumer(product); // 实例化一个消费者
new Thread(p).start(); // 开启生产者线程
new Thread(c).start(); // 开启消费者线程
}
/**
* 生产者线程
*/
static class Producer implements Runnable {
private Product product;
public Producer(Product product) {
this.product = product;
}
public void run() {
while (true) {
// 同步代码锁
synchronized (product) {
try {
while (product.getMax() == product.size()) {
// 产品栈已经满,不需要再生产,执行线程等待操作
System.out.println("产品栈已满,生产者休息中......");
product.wait();
}
// 产品栈不足,开始生产
Object newObj = new Object();
product.add(newObj);
System.out.println("Producer 生产了一个产品,目前产品栈大小为:"
+ product.size());
// 生产一个产品之后,线程开始睡眠
Thread.sleep((long) Math.random() * 3000);
// 通知消费者,有新产品
product.notify();
} catch (Exception e) {
}
}
}
}
}
/**
* 消费者线程
*/
static class Consumer implements Runnable {
private Product product;
public Consumer(Product product) {
this.product = product;
}
public void run() {
while (true) {
// 同步代码锁
synchronized (product) {
try {
while (product.size() == 0) {
// 产品栈已空,不可以再消费,执行线程等待操作
System.out.println("产品栈为空,消费者等待中......");
product.wait();
}
// 产品栈有商品,开始消费
product.remove();
System.out.println("Consumer 消费了一个产品,目前产品栈大小为:"
+ product.size());
// 消费一个产品之后,线程开始睡眠
Thread.sleep((long) Math.random() * 3000);
// 通知生产者,消费了一个产品
product.notify();
} catch (Exception e) {
}
}
}
}
}
static class Product {
// 使用list集合模拟一个产品栈
private List<Object> goods = new LinkedList<Object>();
private int max = 10; // 最大产品数量
public void add(Object obj) {
goods.add(obj);
}
public void remove() {
if (goods.size() > 0) {
goods.remove(goods.size() - 1);
}
}
public int size() {
return goods.size();
}
public int getMax() {
return this.max;
}
public void setMax(int max) {
this.max = max;
}
}
}
java.util.concurrent并发包
几乎java.util.concurrent 中的所有类都是在 ReentrantLock 之上构建的,ReentrantLock 则是在原子变量类的基础上构建的
Semaphore(信号量)
- Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。
- 应用场景
- Semaphore可以用于做流量控制,特别公用资源有限的应用场景,比如数据库连接。假如有一个需求,要读取几万个文件的数据,因为都是IO密集型任务,我们可以启动几十个线程并发的读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,这时我们必须控制只有十个线程同时获取数据库连接保存数据,否则会报错无法获取数据库连接。这个时候,我们就可以使用Semaphore来做流控
- 使用方法Semaphore的构造方法Semaphore(int permits) 接受一个整型的数字,表示可用的许可证数量。Semaphore(10)表示允许10个线程获取许可证,也就是最大并发数是10。Semaphore的用法也很简单,首先线程使用Semaphore的acquire()获取一个许可证,使用完之后调用release()归还许可证。还可以用tryAcquire()方法尝试获取许可证。
原子变量
java.util.concurrent.atomic包中提供了原子变量的9种风格(AtomicInteger、AtomicLong、 AtomicReference、AtomicBoolean等,其原子地更新一对值)
CountDownLatch
- 利用它可以实现类似计数器的功能; 比如有一个任务A,它要等待其他4个任务执行完毕之后才能执行,就可以利用CountDownLatch来实现
例:假如有Thread1、Thread2、Thread3、Thread4四条线程分别统计C、D、E、F四个盘的大小,所有线程都统计完毕交给Thread5线程去做汇总,实现代码如下:
public class CountDownLatchTest { private static CountDownLatch count = new CountDownLatch(4); private static ExecutorService service = Executors.newFixedThreadPool(6); public static void main(String args[]) throws InterruptedException { for (int i = 0; i < 4; i++) { service.execute(() -> { // 模拟任务耗时 try { int timer = new Random().nextInt(5); TimeUnit.SECONDS.sleep(timer); System.out.printf("%s时完成磁盘的统计任务,耗费%d秒.\n", new Date().toString(), timer); // 任务完成之后,计数器减一 count.countDown(); } catch (InterruptedException e) { e.printStackTrace(); } }); } // 主线程一直被阻塞,知道count的计数器被设置为0 count.await(); System.out.printf("%s时全部任务都完成,执行合并计算.\n", new Date().toString()); service.shutdown(); } }
CyclicBarrier回环栅栏
- 通过它可以实现让一组线程等待至某个状态之后再全部同时执行。叫做回环是因为当所有等待线程都被释放以后,CyclicBarrier可以被重用。我们暂且把这个状态就叫做barrier,当调用await()方法之后,线程就处于barrier了
- 例子:假若有若干个线程都要进行写数据操作,并且只有所有线程都完成写数据操作之后,这些线程才能继续做后面的事情
CountDownLatch VS CyclicBarrier
- CountDownLatch和CyclicBarrier都能够实现线程之间的等待,只不过它们侧重点不同:CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行
- CountDownLatch是不能够重用的,而CyclicBarrier是可以重用的。
Fork-Join 框架:
并行分解方法,执行一个任务将首先分解(fork)为多个子任务,完成之后再合并(join)
Callable和FutureTask
参考链接
Android基础知识总结
Android架构层次

android系统架构分从下往上为Linux内核层、运行库、应用程序框架层和应用程序层
- Linux内核层:负责硬件的驱动程序、网络、电源、系统安全以及内存管理等功能。
- 运行库和android runtion:运行库:即c/c++函数库部分,大多数都是开放源代码的函数库,例如webkit,该函数库负责android网页浏览器的运行;例如标准的c函数库libc、openssl、sqlite等,当然也包括支持游戏开发的2dsgl和3dopengles,在多媒体方面有mediaframework框架来支持各种影音和图形文件的播放与显示,如mpeg4、h.264、mp3、aac、amr、jpg和png等众多的多媒体文件格式。Androidruntion负责解释和执行生成的dalvik格式的字节码
- 应用软件架构:java应用程序开发人员主要是使用该层封装好的api进行快速开发的。
- 应用程序层:该层是java的应用程序层,android内置的googlemaps、email、IM、浏览器等,都处于该层,java开发人员工发的程序也处于该层,而且和内置的应用程序具有平等的地位,可以调用内置的应用程序,也可以替换内置的应用程序
ANR的产生原因以及解决方法
- ANR由Activity manager和windows manager来负责监听,你的应用程序所做的事情如果在主线程里占用了大长时间的话,就会引发ANR对话框,因为你的应用程序并没有给自己机会来处理输入事件或者Intent广播
- 产生原因: ①Activity 5s没有响应输入事件,比如按键,触摸事件②广播接收器在10s没有处理完毕事件 ③Service在20s之类没有完成事件处理
- 解决方法: 不在主线程进行网络请求,磁盘读取,位图修改,更新UI等耗时操作,而应该采用子线程来完成,完成之后通过Handler通知主线程
- 如何定位ANR:①检查log文件并分析LogCat输出,查看CPU使用量等信息; ②从/data/anr/目录下的trace.txt文件查看app调用栈信息; ③代码检查
Android 界面卡顿怎么处理?Link
Android子线程和UI线程交互的5种方式
handler: 参考“实习项目总结”
AsyncTask: 参考“实习项目总结”
Activity.runOnUIThread(Runnable)
子线程更新UI
new Thread() { public void run() { //这儿是耗时操作,完成之后更新UI; runOnUiThread(new Runnable(){ @Override public void run() { //更新UI imageView.setImageBitmap(bitmap); } }); } }.start();非Activity更新UI
Activity activity = (Activity) imageView.getContext(); activity.runOnUiThread(new Runnable() { @Override public void run() { imageView.setImageBitmap(bitmap); } });View.Post(Runnable)
imageView.post(new Runnable(){ @Override public void run() { imageView.setImageBitmap(bitmap); } });View.PostDelayed(Runnabe,long)
Activity四种启动模式和生命周期
- Application: 应用程序是组件的集合,manifest文件中展现了application中组件的结构,加载app时会根据manifest去加载和实例化组件
- Process: 一个应用程序占据一个进程,一个运行中的dalvik虚拟机实例就占据一个进程; 但是我们可以给组件设置android:process = “name”来让组件运行在独立进程中
- Task: 一组以栈的形式来进行管理的相互关联的activity的集合,它是存在于framework层的一个跨应用的概念,控制界面的跳转和返回;task中所有的activity在一个叫做back stack的栈中进行管理
- 四种启动模式
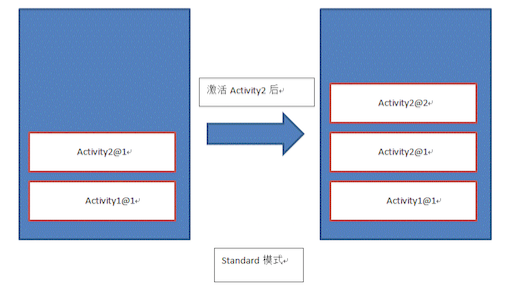
- standard: 默认的lauchmode, 同一个activity可以被实例化多次,在一个task栈中可以同时存在一个activity的多个实例,每次startActivity就新建一个实例入栈
- singleTop: 先检查栈顶是否是该activity的实例,是则重用该实例,并且调用该实例的onNewIntent()方法,否则要新建实例压入栈顶

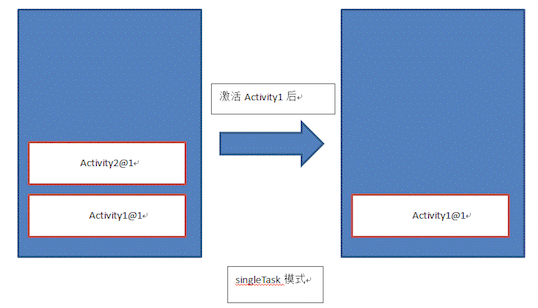
- singleTask: 先检查栈中是否包含该activity的实例,是则重用该实例,清理该实例上的所有activity并将其显示给用户;否则新建实例压入back stack
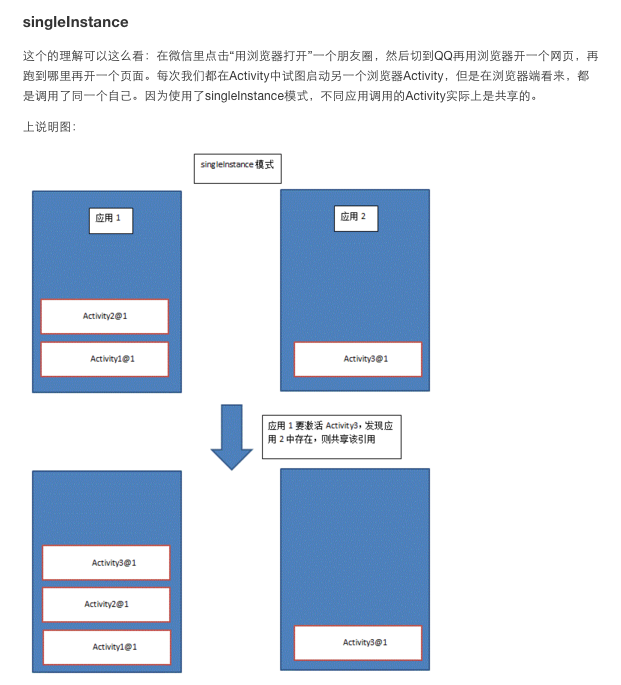
- singleInstance: 以singleInstance模式启动的Activity具有全局唯一性,即整个系统中只会存在一个这样的实例;而且具备独占性,以该模式启动的Activity不能与其他Activity共存在一个task中
- standard: 默认的lauchmode, 同一个activity可以被实例化多次,在一个task栈中可以同时存在一个activity的多个实例,每次startActivity就新建一个实例入栈
Activity以及Fragment生命周期:
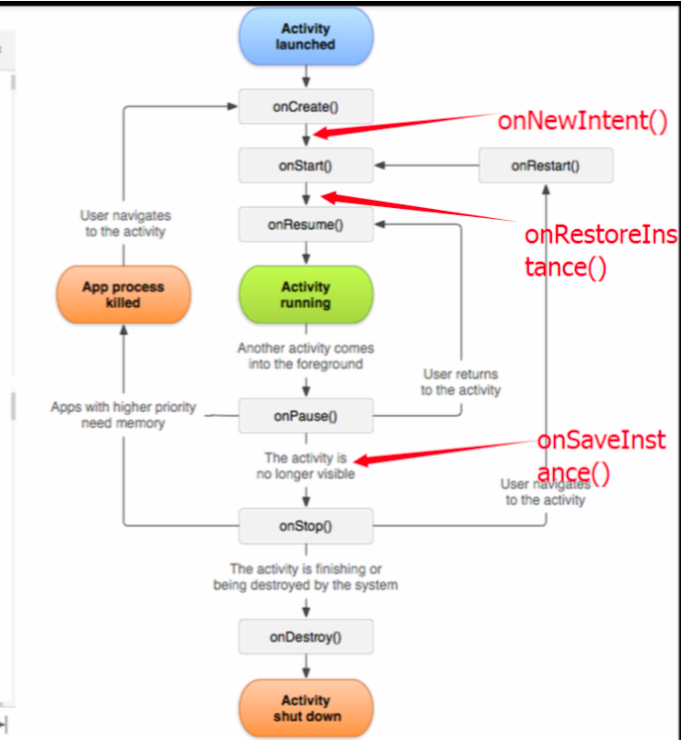
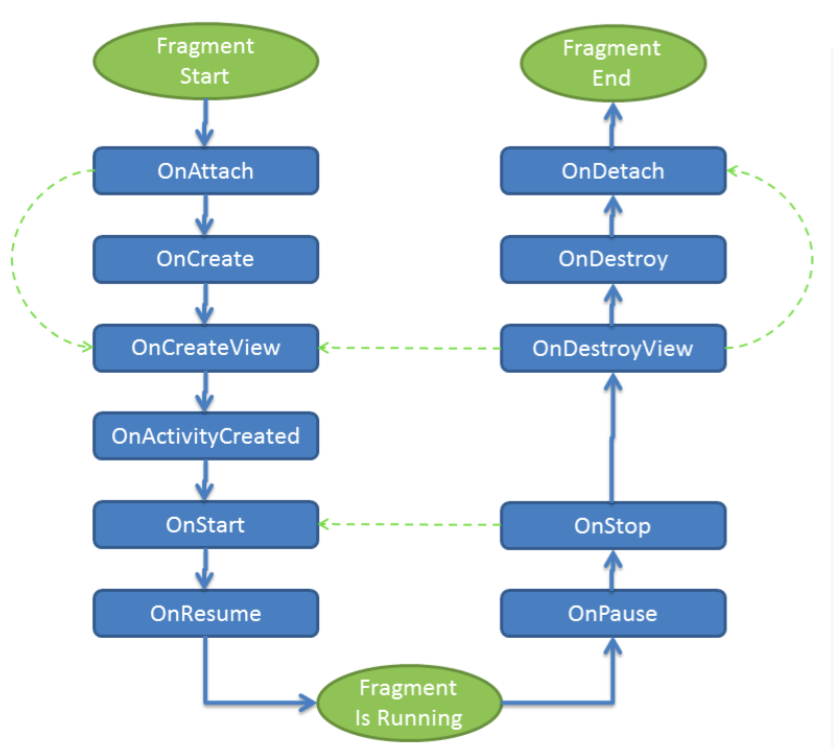
Activity切换时生命周期交集
- 当一个activity A启动了另外一个activity B,它们的生命周期是有交叉的
- 首先A的onPause()被调用;之后B的onCrate(), onStart()及onResume() 方法会被调用(此时B拥有用户焦点);最后,如果A在屏幕上不可见,onStop()方法被调用;
- 因此,我们在两个activities中传递数据,或者共享资源时(如数据库连接),需要在前一个activity的onPause()方法而不是onStop()方法中进行
onSaveInstanceState() 和 onRestoreInstanceState(): Link
①当某个activity变得”容易”被系统销毁时,该activity的onSaveInstanceState()就会被执行,除非该activity是被用户主动销毁的,例如当用户按BACK键的时候;他的调用有5种情况:(1)、当用户按下HOME键时:这是显而易见的,系统不知道你按下HOME后要运行多少其他的程序,自然也不知道activity A是否会被销毁,因此系统会调用onSaveInstanceState(),让用户有机会保存某些非永久性的数据。以下几种情况的分析都遵循该原则 (2)、长按HOME键,选择运行其他的程序时。(3)、按下电源按键(关闭屏幕显示)时。(4)、从activity A中启动一个新的activity时。(5)、屏幕方向切换时,例如从竖屏切换到横屏时。在屏幕切换之前,系统会销毁activity A,在屏幕切换之后系统又会自动地创建activity A,所以onSaveInstanceState()一定会被执行,且也一定会执行onRestoreInstanceState()。
②onRestoreInstanceState()被调用的前提是,activity A“确实”被系统销毁了,而如果仅仅是停留在有这种可能性的情况下,则该方法不会被调用,例如,当正在显示activity A的时候,用户按下HOME键回到主界面,然后用户紧接着又返回到activity A,这种情况下activity A一般不会因为内存的原因被系统销毁,故activity A的onRestoreInstanceState方法不会被执行 此也说明上二者,大多数情况下不成对被使用。如果一个以SingleTask启动的的Activity实例,再新建一个该实例,Activity的执行流程???singleTask保证了在栈中Activity的唯一性,如果被SingleTask标记的Activity处于栈底,上面的Activity都会被pop出栈,这个时候被标记过SingleTask的Activity生命周期会做出调整:onNewIntent->onStart->onResume, 不再调用onCreate函数
- android:taskAffinity:每个Activity都有taskAffinity属性,这个属性指出了它希望进入的Task。如果一个Activity没有显式的指明该 Activity的taskAffinity,那么它的这个属性就等于Application指明的taskAffinity,如果 Application也没有指明,那么该taskAffinity的值就等于包名;例如 android:taskAffinity=””的意思是不依附于任何task,也就是自己新建一个task
Service
Service默认运行在主线程,Service主要运行在后台执行一些监测行为或者其他加载网页等后台操作,可以通过iBinder或者广播与Activity进行交互
- Service两种类型:本地和远程service:
- 本地服务运行于主进程上的主线程,主进程被杀死后,服务便会终止;因为是在同一进程,因此不需要IPC,也不需要AIDL.
- 远程服务运行于独立进程的主线程,不受其他进程影响,有利于为多个进程提供服务;但是会占用一定资源,并且使用AIDL进行IPC通信;对应的独立进程的名字格式为所在包名加上指定android:process字符串。
- 两种启动模式: 具体区别Link
- startService方法一旦服务开启跟开启者就没有任何关系了;开启者退出了,服务还在后台长期的运行;开启者不能调用服务里面的方法
- 多次调用startService,该Service只能被创建一次,即该Service的onCreate方法只会被调用一次。但是每次调用startService,onStartCommand方法都会被调用;通过只能调用Context.stopService()方法结束服务
- bindService的方式开启并绑定服务,绑定者挂了,服务也会跟着挂掉.绑定者可以调用服务里面的方法
- 第一次执行bindService时,onCreate和onBind方法会被调用,但是多次执行bindService时,onCreate和onBind方法并不会被多次调用,即并不会多次创建服务和绑定服务;可以通过调用unbindService()方法来结束服务,调用该方法也会导致系统调用服务的onUnbind()—>onDestroy()方法
- 注意:对于既使用了startService同时也使用了bindService启动的服务我们如果需要停止该服务,应该同时调用stopService与unbindService方法;单独调用unbindService将不会停止Service,而必须调用stopService或Service的stopSelf 来停止服务
- onDestroy方法中做清理工作例如停止在Service中创建并运行的线程。
- 绑定者Activity如何调用service里的方法呢?
- 第一步自定义Service,在其内部重写onBind函数返回一个实现IBinder接口或者继承Binder的对象给绑定者—-这个自定义Binder是一个内部类,提供一个可以间接调用服务或者直接返回service对象的方法
- 第二步在Activity中调用bindService方法,服务成功绑定之后,新建一个ServiceConnection的匿名内部类对象,在回调方法onServiceConnected中会传递过来一个IBinder对象给Activity使用
Service生命周期
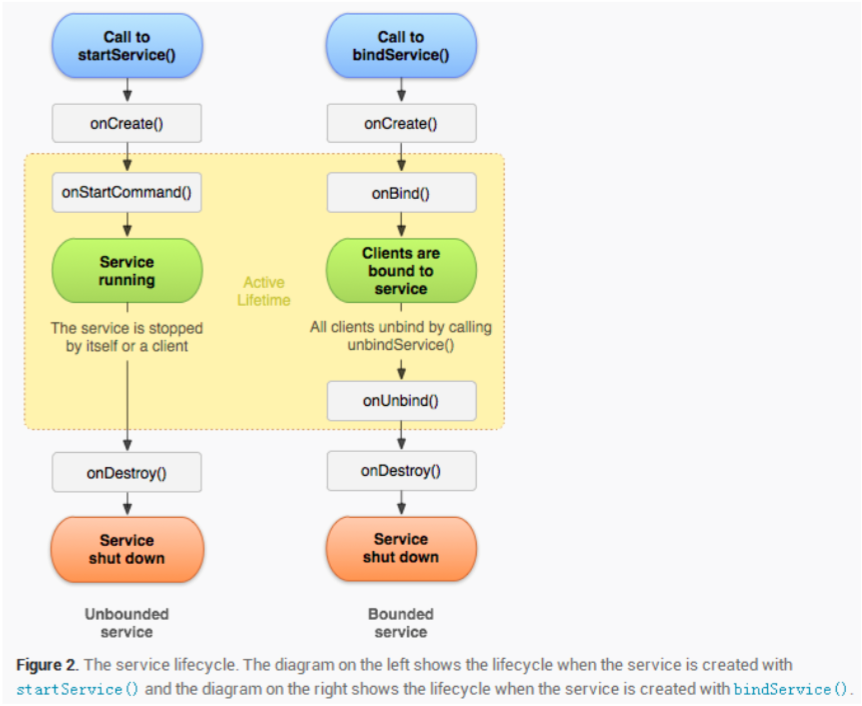
Service与Activity的通信机制
- 广播接收器:
- iBinder机制:
- IntentService
- 为什么要用IntentService如果Service将要运行耗时或者可能被阻塞的操作时,例如直接把耗时操作放在 Service 的 onStartCommand()方法中可能会出现ANR错误;所以应该在Service中重新启动一个新的线程来进行这些操作,这时我们就可以用IntentService
- IntentService内部原理IntentService是一个用来处理异步请求的Service类的子类,当客户端通过startService(Intent)方法传递多个请求给IntentService;IntentService会在onCreate函数中新建HandlerThread去执行这些耗时操作,并新建ServiceHandler对象处理消息,当启动一个IntentService的时候接下来会调用onstart方法,该方法会给ServiceHandler发送消息,在ServiceHandler的handleMessage回调函数中调用onHandleIntent函数,因此我们可以在这个onHandleIntent方法里面处理我们的耗时工作;所以IntentService不仅有Service的功能,还有Handler处理和循环消息的功能
- IntentService对多个异步请求的处理流程IntentService使用队列的方式将请求的Intent加入队列,然后开启一个工作线程来处理队列中的Intent,对于异步的多次startService请求,IntentService会处理完成一个之后再处理第二个,每一个请求都会在一个单独的worker thread中处理,不会阻塞应用程序的主线程;当任务执行完后,IntentService 会自动停止,而不需要我们去手动控制。
- Service后台保活:
- 提高Service的优先级或者提高Service所在进程的优先级:这个,也只能说在系统内存不足需要回收资源的时候,优先级较高,不容易被回收;实现方法有
①startForeground()方法来设置 Service为前台服务,优先级和正在运行的 Activity类似
②在AndroidManifest.xml文件中对于intent-filter可以通过android:priority = “1000”这个属性设置最高优先级,1000是最高值,如果数字越小则优先级越低 - 在onDestroy方法里重启service:这个倒还算挺有效的一个方法,但是,直接干掉进程的时候,onDestroy方法都进不来,更别想重启了
- broadcast广播:和第3种一样,没进入onDestroy,就不知道什么时候发广播了,另外,在Android4.4以上,程序完全退出后,就不好接收广播了,需要在发广播的地方特定处理
- Service的onStartCommand方法返回START_STICKY,这个也主要是针对系统资源不足而导致的服务被关闭。四个返回值参考link:start_sticky、start_no_sticky、START_REDELIVER_INTENT、START_STICKY_COMPATIBILITY
- App进程之间互相唤醒
- 通过JNI的方式(NDK编程),fork()出一个子线程作为守护进程,轮询监听服务状态。守护进程(Daemon)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。而守护进程的会话组和当前目录,文件描述符都是独立的。后台运行只是终端进行了一次fork,让程序在后台执行,这些都没有改变。
- 提高Service的优先级或者提高Service所在进程的优先级:这个,也只能说在系统内存不足需要回收资源的时候,优先级较高,不容易被回收;实现方法有
BroadcastReceiver
广播接收器用于过滤接收并响应来自其他应用程序或者系统的广播消息;每次广播到来时, 会重新创建 BroadcastReceiver对象,并且调用onReceive()方法,执行完以后,该对象即被销毁。当onReceive()方法在 10 秒内没有执行完毕,就会导致ANR。如果需要执行长任务,那么就有必要使用Service;BroadcastReceiver会堵塞主线程。唯有onReceive()结束,主线程才得以继续进行。
- 种类和特点:
- 全局广播包括有序广播、同步广播等,即发出去的广播可以被其他任何应用程序接收到,并且我们也可以接收来自于其他任何应用程序的广播。
- 全局广播跨进程必然会造成安全问题,于是便有了本地广播:即只能在本应用程序中发送和接收广播。这就要使用到了LocalBroadcastManager这个类来对广播进行管理。
- 静态注册和动态注册:
ContentProvider
Android View事件分发机制
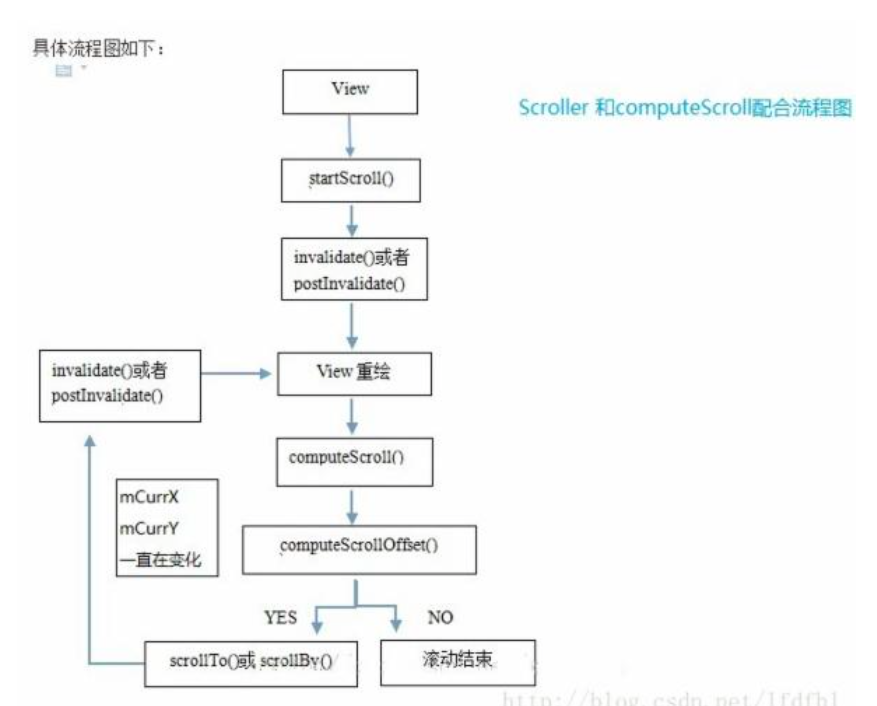
Android Touch事件分发
- Touch事件传递的相关函数有dispatchTouchEvent(决定是否分发事件的函数)、onInterceptTouchEvent(决定是否截停事件的函数)、onTouchEvent(决定是否消费本次事件的函数)
- Touch事件会被封装成MotionEvent对象,该对象封装了手势按下、移动、松开等动作;事件类型分为ACTION_DOWN, ACTION_UP, ACTION_MOVE, ACTION_POINTER_DOWN, ACTION_POINTER_UP, ACTION_CANCEL,每个事件都是以ACTION_DOWN开始ACTION_UP结束。
- Touch事件通常从Activity#dispatchTouchEvent发出,只要没有被消费,会一直往下传递,到最底层的View; 如果Touch事件传递到的每个View都不消费事件,那么Touch事件会反向向上传递,最终交由Activity#onTouchEvent处理.
- Touch事件相关的类有View、ViewGroup、Activity, onInterceptTouchEvent为ViewGroup特有,可以拦截事件; Down事件到来时,如果一个View没有消费该事件,那么后续的MOVE/UP事件都不会再给它;OnTouchListener优先于onTouchEvent()对事件进行消费
- Touch事件分发详细图示

Android平台中实现数据存储的5种方式
- 使用SharedPreferences存储数据:SharedPreferences是Android平台上一个轻量级的存储类,本质是基于XML文件存储key-value键值对数据,主要是保存一些常用的配置信息,提供了Long长整形、Int整形、String字符串型的保存。它分为多种权限,可以全局共享访问,最终是以xml方式来保存。SharedPreferences对象本身只能获取数据而不支持存储和修改,存储修改是通过Editor对象实现。
- 存储步骤:①根据Context获取SharedPreferences对象 ②利用edit()方法获取Editor对象。 ③通过Editor对象存储key-value键值对数据。 ④通过commit()方法提交数据。
- 文件存储数据
- SQLite数据库存储数据
- 使用ContentProvider存储数据
- 网络存储数据
Android 屏幕适配方法总结
Android进程间通信方法
- AIDL+Binder机制
- AIDL:即Android接口定义语言,一种帮助实现Binder通信的工具。由于Android不同的进程不能共享内存,所以为了解决进程间通讯的问题,Android使用一种接口定义语言来公开服务的接口,本质上,AIDL非常像一个接口,通过公开接口,让别的进程调用该接口,从而实现进程间的通讯。具体用法: 只要用几条简单的函数声明,AIDL就会帮忙生成一个JAVA文件,包括了一个Proxy和Stub的访问接口,以及用于它们之间通信的Parcel,并保证Parcel的输入输出的顺序一致性,其中Proxy用于客户端进程,Stub用于Service端进程.AIDL基本用法
- Binder机制:Android进程间通信是通过Binder来实现的,Binder机制使本地对象能够调用远程对象的方法,在不同进程中传递单向/双向消息。远程Service在Client绑定服务时,会在onBind()的回调中返回一个Binder,当Client调用bindService()与远程Service建立连接成功时,会拿到远程Binder实例,从而使用远程Service提供的服务。Binder优点是基于C/S通信模式,传输过程只需要一次拷贝,且为Client添加UID/PID身份,性能和安全性更好,并且Binder可以建立私有通道,这是linux的通信机制所无法实现的,因此Android进程间通信使用了Binder。
- Binder通信模型: Android系统Binder机制中的四个组件Client、Server、Service Manager和Binder驱动程序的关系如下图
- Client、Server和Service Manager实现在用户空间中,Binder驱动程序实现在内核空间中
- Binder驱动程序和Service Manager在Android平台中已经实现,开发者只需要在用户空间实现自己的Client和Server
- Binder驱动程序提供设备文件/dev/binder与用户空间交互,Client、Server和Service Manager通过open和ioctl文件操作函数与Binder驱动程序进行通信
- Client和Server之间的进程间通信通过Binder驱动程序间接实现
- Service Manager是一个守护进程,用来管理Server,并向Client提供查询Server接口的能力
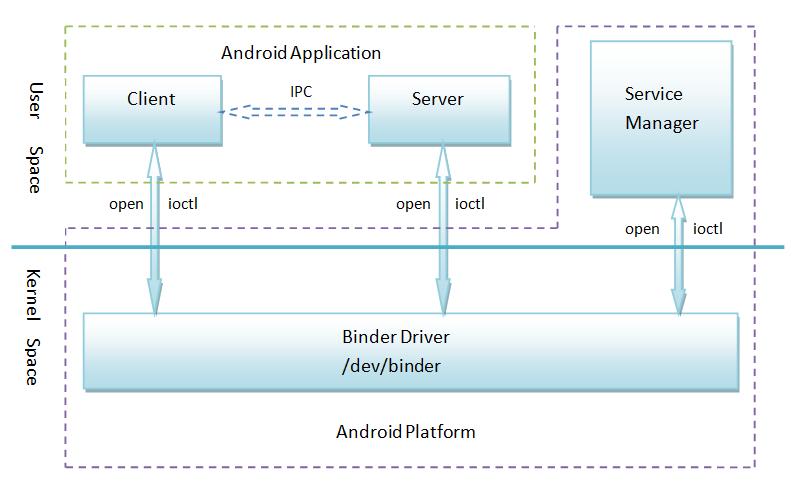
- Client、Server和Service Manager实现在用户空间中,Binder驱动程序实现在内核空间中
- Binder CS通信流程:
- Server作为众多Service的拥有者,当它想向Client提供服务时,得先去Service Manager(以后缩写成SM)那儿注册自己的服务。Server可以向SM注册一个或多个服务。
- Client作为Service的使用者,当它想使用服务时,得向SM申请自己所需要的服务。Client可以申请一个或多个服务。
- ServiceManagerSM一方面管理Server所提供的服务,同时又响应Client的请求并为之分配相应的服务。
- Messenger:Messenger是基于AIDL实现的,服务端(被动方)提供一个Service来处理客户端(主动方)连接,维护一个Handler来创建Messenger,在onBind时返回Messenger的binder。
双方用Messenger来发送数据,用Handler来处理数据。Messenger处理数据依靠Handler,所以是串行的,也就是说,Handler接到多个message时,就要排队依次处理 - Socket通信: 在服务端定义ServerSocket并使用一个while循环监听客户端端口,客户端使用Socket来请求端口,连通后就可以进行通信
Android数据共享
- ContentProvider: 系统四大组件之一,底层也是Binder实现,主要用来为不同应用程序之间提供数据共享;可以用文件,内存数据,数据库等一切来充当数据源
- Bundle/Intent传递数据:可传递基本类型,String,实现了Serializable或Parcellable接口的数据结构。Serializable是Java的序列化方法,Parcellable是Android的序列化方法,前者代码量少,但I/O开销较大,一般用于输出到磁盘或网卡;后者实现代码多,效率高,一般用户内存间序列化和反序列化传输
- 本地文件共享:对同一个文件先后写读,从而实现传输,Linux机制下,可以对文件并发写,所以要注意同步。顺便一提,Windows下不支持并发读或写。
SharedPreferences:Preference提供了一种轻量级的数据存取方法,应用场合主要是数据比较少的配置信息。它以“键-值”(是一个Map)对的方式将数据保存在一个XML配置文件中
Context otherAppContext = createPackageContext("com.gary.appdisplaycontrol", Context.CONTEXT_IGNORE_SECURITY); SharedPreferences sharedPreferences = otherAppContext.getSharedPreferences("preferences",Context.MODE_WORLD_READABLE|Context.MODE_MULTI_PROCESS)
Json VS XML
Android安全
- 错误导出组件
- 参数校验不严
- WebView引入各种安全问题,webview中的js注入
- 不混淆、不防二次打包
- 明文存储关键信息
- 错误使用HTTPS
- 山寨加密方法
- 滥用权限、内存泄露、使用debug签名
设备横竖屏切换的时候,接下来会发生什么?
- 不设置Activity的android:configChanges时,切屏会重新调用各个生命周期,切横屏时会执行一次,切竖屏时会执行两次
- 设置Activity的android:configChanges=”orientation”时,切屏还是会重新调用各个生命周期,切横、竖屏时只会执行一次
- 设置Activity的android:configChanges=”orientation|keyboardHidden”时,切屏不会重新调用各个生命周期,只会执行onConfigurationChanged方法
谈谈你对Android中Context的理解?
Context:包含上下文信息(外部值) 的一个参数. Android 中的 Context 分三种,Application Context ,Activity Context ,Service Context.
它描述的是一个应用程序环境的信息,通过它我们可以获取应用程序的资源和类,也包括一些应用级别操作,例如:启动一个Activity,发送广播,接受Intent信息等
如何缩减APK包大小?
- 代码
保持良好的编程习惯,不要重复或者不用的代码,谨慎添加libs,移除使用不到的libs。
使用proguard混淆代码,它会对不用的代码做优化,并且混淆后也能够减少安装包的大小。
native code的部分,大多数情况下只需要支持armabi与x86的架构即可。如果非必须,可以考虑拿掉x86的部分。 - 资源
使用Lint工具查找没有使用到的资源。去除不使用的图片,String,XML等等。 assets目录下的资源请确保没有用不上的文件。
生成APK的时候,aapt工具本身会对png做优化,但是在此之前还可以使用其他工具如tinypng对图片进行进一步的压缩预处理。
jpeg还是png,根据需要做选择,在某些时候jpeg可以减少图片的体积。 对于9.png的图片,可拉伸区域尽量切小,另外可以通过使用9.png拉伸达到大图效果的时候尽量不要使用整张大图。 - 策略
有选择性的提供hdpi,xhdpi,xxhdpi的图片资源。建议优先提供xhdpi的图片,对于mdpi,ldpi与xxxhdpi根据需要提供有差异的部分即可。
尽可能的重用已有的图片资源。例如对称的图片,只需要提供一张,另外一张图片可以通过代码旋转的方式实现。
能用代码绘制实现的功能,尽量不要使用大量的图片。例如减少使用多张图片组成animate-list的AnimationDrawable,这种方式提供了多张图片很占空间。
Android插件化与动态加载
- 为什么要插件化???And它是什么?有什么好处?当一个app的方法数超过了一个 Dex 最大方法数 65535 的上限,因而便有了插件化的概念,Android插件化指将一个程序划分为不同的部分,也就是将一个App划分为多个插件(Apk或相关格式)比如一般App的皮肤样式就可以看成一个插件; 插件化的好处包括:(1) 模块解耦(2) 可以动态升级(3) 高效并行开发(编译速度更快) (4) 按需加载,内存占用更低 (5) 节省升级流量
- 插件化的原理实际是 Java ClassLoader 的原理: Android 有自己的 ClassLoader,分为 dalvik.system.DexClassLoader 和 dalvik.system.PathClassLoader,区别在于:
- PathClassLoader: 不能直接从 zip 包中得到 dex,因此只支持直接操作 dex 文件或者已经安装过的 apk(因为安装过的 apk 在 cache 中存在缓存的 dex 文件)
- DexClassLoader 可以加载外部文件系统中的 apk、jar 或 dex文件,并且会在指定的 outpath 路径存放其 dex 文件。
- 此外还有URLClassLoader :可以加载java中的jar,但是由于dalvik不能直接识别jar,所以此方法在Android中无法使用,尽管还有这个类
- Android热加载或Android动态部署指App在运⾏状态下动态加载某个模块,从而新增功能或改变某⼀部分行为. 例如一个app(称之为宿主程序)去本地文件中动态加载apk文件并将其放在自己的进程中执行
- 为什么有dex文件以及为什么要有DexClassLoader???Android应用程序,本质上使用的是java开发,使用标准的java编译器编译出Class文件,和普通的java开发不同的地方是把class文件再重新打包成dex类型的文件,这种重新打包会对Class文件内部的各种函数表、变量表等进行优化,最终产生了dex文件。dex文件是一种经过android打包工具优化后的Class文件,因此加载这样特殊的Class文件就需要特殊的类装载器;所以android中提供了DexClassLoader类
AsyncTask和Handler,Looper
- 网络请求交互:参见百度锁屏项目
- Android AsynTask实现多任务下载管理:
private class DemoAsyncTask extends AsyncTask<String, Integer, Bitmap> {
@Override
protected void onPreExecute() {
super.onPreExecute();
}
@Override
protected Bitmap doInBackground(String... params) {
return null;
}
@Override
protected void onPostExecute(Bitmap result) {
super.onPostExecute(result);
}
@Override
protected void onProgressUpdate(Integer... progress) {
super.onProgressUpdate(progress);
}
@Override
protected void onCancelled() {
super.onCancelled();
}
}
- AsyncTask
- params 启动任务执行的输入参数,比如HTTP请求的URL(doInBackground函数的参数类型)
- progress 后台任务执行的百分比(onProgressUpdate函数的参数类型)
- result 后台执行任务最终返回的结果,比如String(doInBackground返回的参数类型
- new AsynTask.execute(url); execute方法内部调用executeOnExecutor()方法,执行之后AsyncTask会把任务交给线程池,由线程池来管理创建Thread和运行Therad执行任务
- 使用AsyncTask类,以下是几条必须遵守的准则:AsyncTask的实例必须在UI thread中创建; execute方法必须在UI thread中调用,并且只能调用一次;3.0版本之后的AsyncTask同时只能执行一个任务,但是提供executeOnExecutor(executor)来接收自定义ThreadPoolExecutor线程池,3.0之前默认为SerialExecutor,其核心线程池的大小是5,线程池总大小为128,缓存任务队列是10
AsyncTask内部实现原理
- AsyncTask的本质是一个线程池,AsyncTask在构造函数中新建一个继承Callable接口的WorkerRunnable类对象,重载call方法,在call方法中执行语句return postResult(doInBackground(mParams));执行doInBackground中的异步任务;然后新建FutureTask接受WorkerRunnable作为参数,提交到线程池执行;在FutureTask的重载done函数中调用get方法接收线程执行的返回结果并定义任务状态变化后的操作(包括失败和成功),再调用postResult方法利用handler(一个static class InternalHandler extends Handler对象)发送message给UI线程
- AsyncTask派生出的子类可以实现不同的异步任务,这些任务都是提交到静态的线程池中执行; 线程池中的工作线程执行doInBackground(mParams)方法执行异步任务
- 当任务状态改变(例如进度更新,执行成功,取消)之后,线程池中的工作线程会向UI线程发送消息,UI线程中的AsyncTask内部的InternalHandler响应这些消息并进行处理;例如:如果当前任务被取消掉了,就会调用onCancelled()方法不再调用onPostExecute方法,如果没有被取消,则调用onPostExecute()方法,这样当前任务的执行就全部结束了
AsyncTask和Handler,Looper之间的区别联系
- AsyncTask是对Handler与Thread的封装。
- AsyncTask在代码上比Handler要轻量级别,但实际上比Handler更耗资源,因为AsyncTask底层是一个线程池,而Handler仅仅就是发送了一个消息队列。但是,如果异步任务的数据特别庞大,AsyncTask线程池比Handler节省开销,因为Handler需要不停的new Thread执行
- AsyncTask的实例化只能在主线程,Handler可以随意,只和Looper有关系
Handler+Looper+MessageQueue异步信息处理系统模型 Link
- Handler+Looper+MessageQueue概念 Looper本质是一个ThreadLocal变量,它持有一个MessageQueue消息队列,负责实现消息循环和消息派发; Handler通过post和sendMessage方法去负责收发Message,包括push新消息到MessageQueue或者接收Looper从其持有的MessageQueue中取出来的消息; MessageQueue是一个FIFO消息队列
异步通信流程:
① 消息分发和处理: 首先一个线程通过调用Looper.prepare(),为自己创建一个唯一的Looper对象,在该Looper对象的构造函数中会执行mQueue = new MessageQueue(quitAllowed);去创建一个消息队列;然后我们新建一个或者多个Handler并重载他们的handleMessage回调函数,用于处理其他线程中发送过来的消息;接下来我们调用Looper.loop方法,在该方法中会建立一个无限循环体,通过调用msg.target.dispatchMessage(msg);函数(其内部调用Handler的handleMessage回调函数)不断地从消息队列中取出message,分发给不同的Handler target.
(注:在主线程中默认新建Looper对象不需要显示调用prepare和loop函数,Looper、MessageQueue和Handler都是在同一个线程中)② Handler发送消息: Handler在初始化时就会调用mLooper = Looper.myLooper(); mQueue = mLooper.mQueue;和Looper以及消息队列相关联,然后在子线程中调用post或者sendMessage方法发送消息插入到消息队列中,这两个函数内部的调用顺序大致为sendMessageDelayed—> sendMessageAtTime—> enqueueMessage,在enqueueMessage函数中会执行msg.target = this;这样Looper就可以识别每条信息来自于哪个Handler,以便于分发消息的正确性
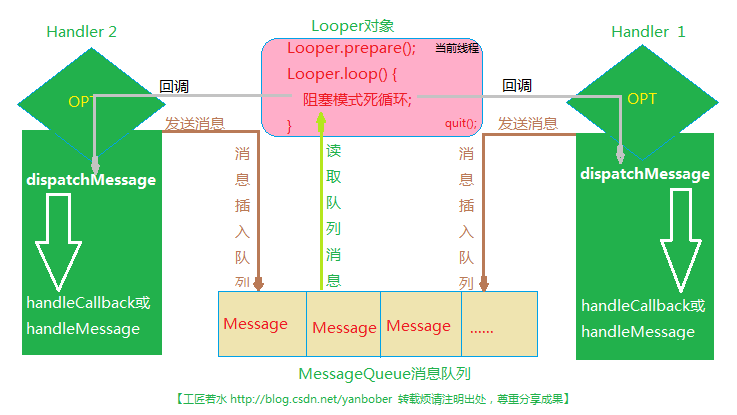
Handler更新UI:Android系统中耗时操作不能放在主线程进行,例如网络请求、数据库操作、复杂计算等逻辑;所以他们一般放在AsyncTask或者新建子线程进行,然后通过Handler发送消息通知主线程;如果这些耗时操作涉及到UI界面的更新,可以借助于(Android系统UI的更新必须放在主线程进行)Handler发送消息给UI线程更新UI
Handler更新UI实例:
// UI线程新建的Handler,在handleMessage()中更新UI private Handler mHandler = new Handler() { public void handleMessage (Message msg) { switch(msg.what) { case MSG_SUCCESS: mImageView.setImageBitmap((Bitmap) msg.obj); break; case MSG_FAILURE: break; } } }; // 子线程中获取网络图片并发送message通知UI线程更新显示图片 Runnable runnable = new Runnable() { @Override public void run() { HttpClient hc = new DefaultHttpClient(); HttpGet hg = new HttpGet("http://www.oschina.net/img/logo.gif"); final Bitmap bm; try { HttpResponse hr = hc.execute(hg); bm = BitmapFactory.decodeStream(hr.getEntity().getContent()); } catch (Exception e) { mHandler.obtainMessage(MSG_FAILURE).sendToTarget(); return; } // Handler发送消息可以new但是最好使用obtainMessage,因为Message内部 // 通过next实现一个缓存消息链表,使用obtain方法获取Message使用完之后系统 // 会调用recycle方法进行回收,节省内存 mHandler.obtainMessage(MSG_SUCCESS,bm).sendToTarget(); } }; new Thread(runnable).start();子线程中Handler结合Looper处理其他线程发送过来的消息实例
class LooperThread extends Thread { public Handler mHandler; public void run() { Looper.prepare(); mHandler = new Handler() { public void handleMessage(Message msg) { } }; Looper.loop(); } }一个线程只能拥有一个Looper实例(该Looper对象可以通过Looper.myLooper()来获取),对应着一个MessageQueue消息队列,但是可以拥有多个Handler; 主线程初始化时默认创建一个Looper对象,可以通过Looper.getMainLooper()来获取他;
- 主线程中可以直接新建Handler,但是子线程中新建Handler需要先调用Looper.prepare()
- 消息队列其实内部实现是一个管道通信机制,当队列为空时线程进入等待状态,不为空时才进入处理消息状态;enqueueMessage方法也分为2种情况,队列为空直接将新message添加到队列头部,否则需要将消息按照时间先后顺序插入到合适位置,因为消息要按照处理时间排序
handler可能引发的内存泄露和解决方案
- 当使用内部类(包括匿名类)来创建Handler的时候,Handler对象会隐式地持有一个外部类对象(通常是一个Activity)的引用。而Handler通常会伴随着一个耗时的后台线程一起出现,这个后台线程在任务执行完毕之后,通过消息机制通知Handler,然后Handler把消息发送到UI线程。然而,如果用户在耗时线程执行过程中关闭了Activity(正常情况下Activity不再被使用,它就有可能在GC检查时被回收掉),由于这时线程尚未执行完,而该线程持有Handler的引用,这个Handler又持有Activity的引用,就导致该Activity暂时无法被回收(即内存泄露)
解决方案:
Handler声明为静态内部类,不再持有外部类Activity,在其内部声明一个Activity的弱引用来操作Activity中的对象
static class TestHandler extends Handler { WeakReference<Activity > mActivityReference; TestHandler(Activity activity) { mActivityReference= new WeakReference<Activity>(activity); } @Override public void handleMessage(Message msg) { final Activity activity = mActivityReference.get(); if (activity != null) { mImageView.setImageBitmap(mBitmap); } } }①在关闭Activity的时候停掉你的后台线程。线程停掉了,就相当于切断了Handler和外部连接的线,Activity自然会在合适的时候被回收;②如果你的Handler是被delay的Message持有了引用,那么使用相应的Handler的removeCallbacks()方法,把消息对象从消息队列移除
- HandlerThread是一个Looper,Handler,Thread的组合实现;在其构造函数中对Looper进行初始化,并提供一个Looper对象给新创建的Handler对象,使得Handler处理消息事件在子线程中处理
实习项目总结
自我介绍 1min 慢,停顿
- 姓名 —-> 学习经历(中大科大软件专业) 基于兴趣和职业规划 —-> 本科到硕士都注重计算机基础知识积累,对Java语言基础,计算机网络/MySQL数据库原理,常见数据结构和算法比较熟悉,例如常见排序,链表,二叉树,队列栈等;平常对移动端和web端研发也具有浓厚兴趣
- 一直以来也比较注重实践,陆续参加了几个实习和项目,提现学习和工作能力(先后参与3份实习和2个校内科研项目,选择与岗位相符的两段经历进行1-2句话简述,做了什么和达到了什么成就)
- 业余爱好,羽毛球,健身,阅读和利用coursera进行业余学习
- 对目标岗位的理解和想法,应聘该岗位的强烈意愿以及自身吻合度
- 经历:前期社会活动兴趣的广泛性+后期对专业的专注性;性格:程序员中的外向型
网易
- 学习Spring框架使用和原理
- 接口实现
- 网易实习时有挑战性的地方以及,最大的贡献
- 自己扮演的角色应该是需求开发者和主动学习者的角色 ①快速学习能力的体现以及快速学习的方法,学习使用redis,Spring框架开发restful 数据接口②沟通与合作:与产品,前端,测试之间分工合作②贡献818的部分核心需求,开奖时服务端通过张连接WebSocket主动推送给app开奖信息;设置一个观察者观察开奖数据;然后查表中未中奖用户的信息进行推送
Kactus
- ECO餐厅食用油回收系统
- Android端缓存机制的实现,采用二级缓存,LRUcache内存缓存和DiskLruCache文件缓存,同时模拟浏览器缓存机制来分析http请求过程的请求头内容来确定cache-control策略
- App请求server数据流程: 当我们第一次打开应用获取图片时,先到网络去下载图片,然后依次存入内存缓存,磁盘缓存;以后每次加载图片的时候都优先去LRUCache内存缓存当中读取,当读取不到的时候则回去DiskLruCache硬盘缓存中读取,而如果硬盘缓存仍然读取不到的话,就从网络上请求原始数据。
- App的二级缓存实现: 变化频繁的小数据(例如订单列表)都采用LRUCache,以
- 缓存管理和清理策略:
- ① 现用方法App根据服务器响应头部里边的expires(缓存过期的时间(绝对时间)),Last-Modified(服务器响应的资源最终修改时间), Cache-Control(资源的有效期)等内容来确定是否需要将数据缓存到DiskLruCache中,以及缓存的保留时间,具体实现 每次请求url得到响应结果时会解析头部Cache-Control去判断该响应资源是否需要缓存以及缓存过期时间等内容;然后将资源URL和这些缓存时间相关的http头部信息(比如expires(缓存过期的时间))一起存储到SQLite数据库,然后每次加载资源都会先根据url查询数据库看本地缓存是否过期,是否需要重新发送网络请求并更新缓存
- ② 其它方法每次去读取缓存文件时先调用File.lastModified()方法得到文件的最后修改时间,与当前时间相减得到已缓存时间,然后根据自定义的缓存时间判断该缓存是否过期,如果过期则重新请求文件,不然直接从缓存加载,这样就能实现缓存文件定时清理
- ③ 每次服务器资源变化时客户端怎么得到通知?, 客户端定时轮询请求某个指定url并解析返回的json判断某些数据是否变化,变化就重新请求该数据; 或者手动刷新,socket长连接
- FIFOFirst In First Out,先进先出;核心原则就是:如果一个数据最先进入缓存中,则应该最早淘汰掉。也就是说,当缓存满的时候,应当把最先进入缓存的数据给淘汰掉。
- LFU:Least Frequently Used,最不经常使用;在一段时间内,数据被使用次数最少的,优先被淘汰。
- LRU: Least Recently Used,最近最少使用策略,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”;简单的说就是缓存一定量的数据,当超过设定的阈值时就把一些最近最少使用的数据删除掉;最常见的实现算法是使用一个链表保存缓存数据,①新数据插入到链表头部;②每当缓存命中(即缓存数据被访问),则将数据移到链表头部;③当链表满的时候,将链表尾部的数据丢弃。LRUCache双向链表+HashMap实现 LRUCache LinkedHashMap实现
- LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。实现:相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据
- Android端缓存机制的实现,采用二级缓存,LRUcache内存缓存和DiskLruCache文件缓存,同时模拟浏览器缓存机制来分析http请求过程的请求头内容来确定cache-control策略
缓存图片举例:
// 获取应用可占内存的1/8作为缓存
int maxSize = (int) (Runtime.getRuntime().maxMemory() / 8);
// 实例化LruCaceh对象
mLruCache = new LruCache<String, Bitmap>(maxSize) {
@Override
protected int sizeOf(String key, Bitmap bitmap) {
return bitmap.getRowBytes() * bitmap.getHeight();
}
};
mDiskLruCache=DiskLruCache.open(getDiskCacheDir(context.getApplicationContext(),
"xxxxx"), getAppVersion(context), 1, DISKMAXSIZE);
// 缓存操作
mLruCache.get(url);
mLruCache.put(url, bitmap);
bitmap = BitmapFactory.decodeStream(mDiskLruCache.get(url).getInputStream(0));
DiskLruCache.Editor editor = mDiskLruCache.edit(key);
OutputStream outputStream = editor.newOutputStream(0);
editor.commit();
采用Java WebSocket编程取代传统的非实时http请求连接模式
为什么要用WebSocket实时交互数据?: 传统Web应用的信息交互过程通常是客户端发出一个请求,服务器端接收和审核完请求后进行处理并返回结果给客户端,然后客户端浏览器将信息呈现出来,但是对于那些实时要求比较高的应用来说,比如说在线游戏、新闻在线播报、RSS 订阅推送等等,当客户端浏览器准备呈现这些信息的时候,这些信息在服务器端可能已经过时了;所以我们考虑采用webSocket 常见的模拟实时应用方法
轮询:最早的一种实现实时 Web 应用的方案。客户端以一定的时间间隔向服务端发出请求,以频繁请求的方式来保持客户端和服务器端的同步。服务器端的数据可能并没有更新但是依然请求,会带来很多无谓的网络传输,所以这是一种非常低效的实时方案。
长轮询:为了降低无效的网络传输,当服务器端没有数据更新的时候,连接会保持一段时间周期直到数据或状态改变或者时间过期,通过这种机制来减少无效的客户端和服务器间的交互
流: 流技术方案通常就是在客户端的页面使用一个隐藏的窗口向服务端发出一个长连接的请求。服务器端接到这个请求后作出回应并不断更新连接状态以保证客户端和服务器端的连接不过期。通过这种机制可以将服务器端的信息源源不断地推向客户端。这种机制需要针对不同的浏览器设计不同的方案来改进用户体验,同时这种机制在并发比较大的情况下,对服务器端的资源是一个极大的考验。
WebSocket原理和建立过程: WebSocket是一个基于TCP连接的双向通道;为了建立一个 WebSocket 连接,客户端浏览器首先要向服务器发起一个 HTTP 请求,这个请求和通常的 HTTP 请求不同,包含了一些附加头信息,其中附加头信息”Upgrade: WebSocket”表明这是一个申请协议升级的 HTTP 请求,服务器端解析这些附加的头信息然后产生应答信息返回给客户端,客户端和服务器端的 WebSocket 连接就建立起来了,双方就可以通过这个连接通道自由的传递信息,并且这个连接会持续存在直到客户端或者服务器端的某一方主动的关闭连接。
@ServerEndpoint("/websocket") public class WebSocketTest { @OnMessage public void onMessage(String message, Session session) throws IOException, InterruptedException { System.out.println("Received: " + message); // Send the first message to the client session.getBasicRemote().sendText("This is the first server message"); // Send 3 messages to the client every 5 seconds int sentMessages = 0; while(sentMessages < 3){ Thread.sleep(5000); session.getBasicRemote(). sendText("This is an intermediate server message. Count: " + sentMessages); sentMessages++; } // Send a final message to the client session.getBasicRemote().sendText("This is the last server message"); } @OnOpen public void onOpen() { System.out.println("Client connected"); } @OnClose public void onClose() { System.out.println("Connection closed"); } }如何使用Encoder和Decoder传输更复杂的数据:Websocket使用Decoder将文本消息转换成Java对象,然后传给@OnMessage方法处理; 而当对象写入到session中时,Websocket将使用Encoder将Java对象转换成文本,再发送给客户端。
整个项目从简单的多线程优化到采用线程池来实现xml数据文件的获取
- 总体项目图
Baidu
Duwear项目短信管理模块: 目的是将手机短信库的变化情况通知到wear端
- SMSObserver继承ContentProvider类实现观察者模式,注册了一个短信数据库的观察者,发生变化该类都会被通知;在重载函数onChange中进行操作比对判断数据库变化情况,只知道变化,但是不知道具体操作?如何判断用户是标为已读还是删除,新建短信
- SmsReceivedListener接口:两个回调函数,作为一个接口参数传到SMSObserver的构造函数中,然后一旦判断是新短信还是短信已读,就调用其回调函数
- SmsRpcService类:继承自上边的接口,在回调函数中将这个操作判断出来发送给手表
- SmsUtils: 4个函数,查询短信数据库,标为已读的数据库操作函数
SMSObserver类中的具体的判断方式和优化过程
- 从维护所有信息的set到只维护未读信息的内容,信息实体占用内存很大,内存优化;
ArrayList到HashSet对比与区别:防止出现重复信息,去重速度很快因为使用HashTable中的hashCode()以及equals进行查找去重;
多次读取unreadSet并对两个set进行比对,removeAll和AddAll求补集并集来比对两个未读信息集合;两个方法都用到了hashCode和equals,所以SmsEntity对象中hashcode和equals方法的同时重载;直接removeAll新set可以判断出哪些信息被标为已读,AddAll新set再removeAll旧set可以判断得到新增加的短信;比如1,2,3和1,2,4,5
java集合中的浅复制和深复制,clone集合不影响原集合
浅复制: 复制后的对象与原对象所有变量的值相同,包括引用变量,浅复制时只会复制引用变量本身,不会复制它指向的对象本身
深复制: 复制后的对象与原对象所有变量的值相同,但是不包括引用变量,深复制时会复制引用变量指向的对象本身,所以引用值发生改变
Clone()方法和Cloneable接口: Cloneable接口是一个不包含方法的标志接口,一个类必须先继承它才能在其内部调用super.clone()方法,否则会抛出不支持clone的异常;clone()方法是一个native方法,拷贝对象时已经包括一部分原对象信息,效率优于使用新建对象再一一复制变量的方式;重写clone()方法需要先调用super.clone()方法,该方法会开辟一块新的内存用于拷贝原对象,将原对象的内容一一复制到新对象的内存空间中,它是一种浅复制;如果要实现深复制,需要对复制的对象中的所有引用变量对应的对象也进行复制(具体操作:重写引用对象的clone方法,在其中调用super.clone,然后在上层对象的重载clone方法中调用该对象的clone方法)
序列化实现深复制: 序列化主要用于将内存中对象状态写入数据库或者文件,以及利用Socket在网络中传输对象;一个对象要能够被序列化需要该类实现Serializable接口,可序列化类的子类默认也是可以被序列化的,不需要再次实现Serializable接口;利用序列化进行深复制的前提是该对象及其内部的引用到的对象都是可序列化的,这样对对象序列化时才能递归地保存对象及其引用对象的数据
deepClone() { //序列化:将内存中对象状态转化为字节流,写入目标输出流 ByteArrayOutoutStream bo=new ByteArrayOutputStream(); ObjectOutputStream oo=new ObjectOutputStream(bo); // oo.writeObject(this); //反序列化:读取源输入流中的字节流重建一个内存中相同状态的对象 ByteArrayInputStream bi=new ByteArrayInputStream(bo.toByteArray()); ObjectInputStream oi=new ObjectInputStream(bi); return(oi.readObject()); }当一个类声明要实现Serializable接口时,只是表明该类参加序列化协议;Java提供的ObjectInputStream和ObjectOutputStream将数据流功能扩展至可读写对象 。在ObjectInputStream中用readObject()方法可以直接读取一个对象,ObjectOutputStream中用writeObject()方法可以直接将对象保存到输出流中; 序列化只能保存对象的非静态成员变量,不能保存任何的成员方法和静态成员变量,而且序列化保存的只是变量的值,对于变量的任何修饰符都不能保存。
- 工厂模式生产手表View:需要生成许多不同的CardView,利用CardFactory中的BuildPage函数
- 简单工厂模式:工程类+抽象产品类+具体产品类;根据参数的不同返回不同类的实例。专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类
- 工厂方法模式: 抽象产品角色,具体产品角色,抽象工厂角色,具体工厂角色;工厂父类负责定义创建产品对象的公共接口,而工厂子类则负责生成具体的产品对象,这样做的目的是将产品类的实例化操作延迟到工厂子类中完成,即通过工厂子类来确定究竟应该实例化哪一个具体产品类;一个抽象产品类,可以派生出多个具体产品类。一个抽象工厂类,可以派生出多个具体工厂类。每个具体工厂类只能创建一个具体产品类的实例。
- 抽象工厂模式: 多个抽象产品类,每个抽象产品类可以派生出多个具体产品类。一个抽象工厂类,可以派生出多个具体工厂类。每个具体工厂类可以创建多个具体产品类的实例。
百度锁屏项目: View的自定义绘制与组合原理过程
网络通信的优化和实现过程http从同步的主线程发送get请求优化为异步的子线程发送post请求, 加强了数据传输的安全性和长度,解决了应用程序无响应的应用体验问题; httpClient和HttpUrlConnection的区别对比;最后学习和使用Volley以及OkHttp通信库
参考链接异步的get和post请求实现过程(HttpUrlConnection)
httpClient和httpUrlConnection, OKHttp对比:
- httpClient是apache的开源实现,API数量多,非常稳定
- httpUrlConnection是java自带的模块: ①可以直接支持GZIP压缩,而HttpClient虽然也支持GZIP,但要自己写代码处理 ②httpUrlConnection直接在系统层面做了缓存策略处理,加快重复请求的速度 ③API简单,体积较小,而且直接支持系统级连接池,即打开的连接不会直接关闭,在一段时间内所有程序可共用
- HttpURLConnection在Android2.2之前有个重大Bug,调用close()函数会影响连接池,导致连接复用失效,需要关闭keepAlive;因此在2.2之前http请求都是用httpClient,2.2之后则是使用HttpURLConnection
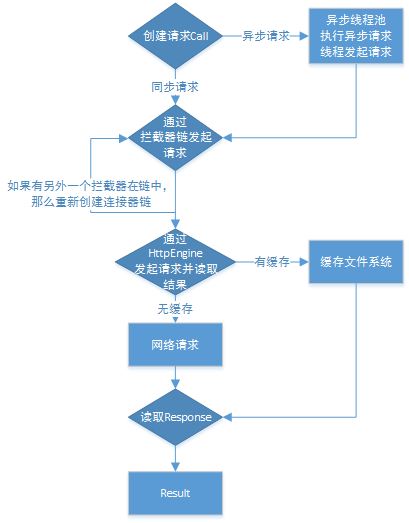
- 但是!!!现在!!!Android不再推荐这两种方式!二是直接使用OKHttp这种成熟方案!支持Android 2.3及其以上版本; 什么是OKHttp?
- Volley原理和OkHttp实现原理和应用方法以及优缺点
- Volley的调用过程,通过 newRequestQueue(…) 函数新建并启动一个请求队列RequestQueue后,只需要往这个RequestQueue不断 add Request 即可
- Volley:Volley 对外暴露的 API,通过 newRequestQueue(…) 函数新建并启动一个请求队列RequestQueue。
- Request:表示一个请求的抽象类。StringRequest、JsonRequest、ImageRequest 都是它的子类,表示某种类型的请求。
- RequestQueue:表示请求队列,里面包含一个CacheDispatcher(用于处理走缓存请求的调度线程)、NetworkDispatcher数组(用于处理走网络请求的调度线程),一个ResponseDelivery(返回结果分发接口),通过 start() 函数启动时会启动CacheDispatcher和NetworkDispatchers。
- HttpStack:处理 Http 请求,返回请求结果。目前 Volley 中有基于 HttpURLConnection 的HurlStack和 基于 Apache HttpClient 的HttpClientStack,也可以内部采用OKHttp实现
- CacheDispatcher.java:继承自Thread,用于调度处理「缓存请求」。启动后会不断从缓存请求队列中取请求处理,队列为空则等待,请求处理结束则将结果传递给ResponseDelivery去执行后续处理。当结果未缓存过、缓存失效或缓存需要刷新的情况下,该请求都需要重新进入NetworkDispatcher去调度处理。
- NetworkDispatcher.java:继承自Thread,用于调度处理「网络请求」。启动后会不断从网络请求队列中取请求处理,队列为空则等待,请求处理结束则将结果传递给ResponseDelivery去执行后续处理,并判断结果是否要进行缓存。
Volley与Activity生命周期联动与取消请求:为了在Activity退出或销毁的时候,取消对应的网络请求,避免网络请求在后台浪费资源;我们使用Volley的话,可以在Activity停止的时候,同时取消所有或部分未完成的网络请求,这些请求将不会被返回给主线程,取消操作一般在onStop()函数里边执行
// 遍历整个Activity中的请求集合,例如List for (Request <?> req : mRequestQueue) { req.cancel(); } // 取消整个队列中的请求 mRequestQueue.cancelAll(this); // 根据RequestFilter或者Tag来终止某些请求 mRequestQueue.cancelAll( new RequestFilter() {}); mRequestQueue.cancelAll(new Object());流程图解:
第一步:主线程根据优先级把请求加入缓存队列
第二步:「缓存调度线程」CacheDispatcher从缓存队列中取出一个请求,如果缓存命中,就读取缓存响应并解析,然后将结果返回到主线程
第三步:缓存未命中,该请求被加入网络请求队列,「网络调度线程」NetworkDispatcher(一个默认值为4的线程池)从网络队列中轮询取出请求,进行HTTP请求传输,解析响应,写入缓存,然后将结果返回到主线程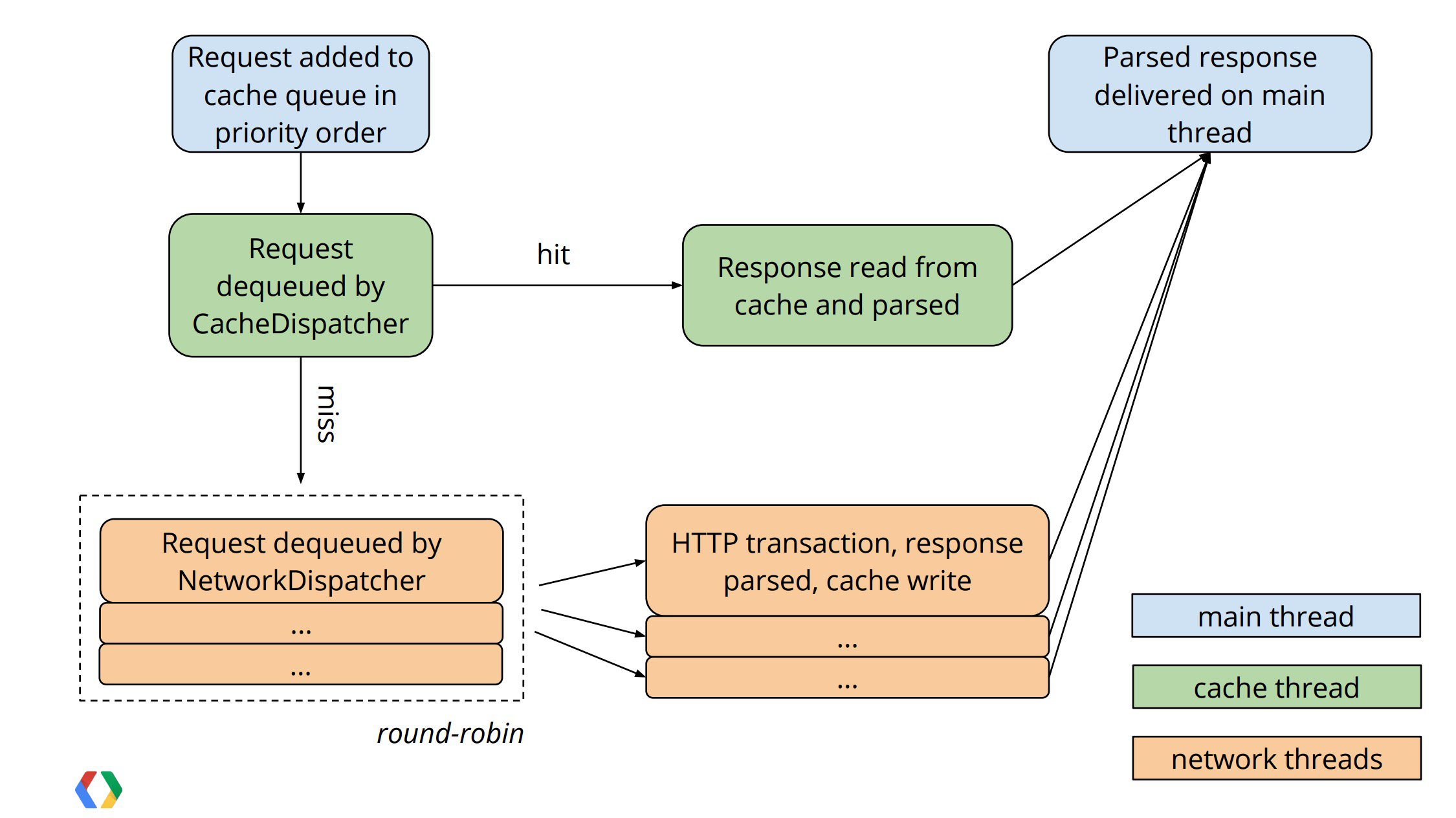
Volley用法
RequestQueue mQueue = Volley.newRequestQueue(context); StringRequest stringRequest = new StringRequest (Method.POST, "http://www.baidu.com", new Response.Listener<String>() { @Override public void onResponse(String response) { Log.d("TAG", response); } }, new Response.ErrorListener() { @Override public void onErrorResponse(VolleyError error) { Log.e("TAG", error.getMessage(), error); } }){ @Override protected Map<String, String> getParams() throws AuthFailureError { Map<String, String> map = new HashMap<String, String>(); map.put("params1", "value1"); map.put("params2", "value2"); return map; } }; mQueue.add(stringRequest);
OkHttp用法源码分析
OkHttpClient mOkHttpClient = new OkHttpClient();
FormEncodingBuilder builder = new FormEncodingBuilder();
builder.add("username","value");
Request request = new Request.Builder()
.url(url)
.post(builder.build())
.build();
mOkHttpClient.newCall(request).enqueue(new Callback(){
@Override
public void onFailure(Request request, IOException e)
{
}
@Override
public void onResponse(final Response response) throws IOException
{
//String htmlStr = response.body().string();
}
});
毕设-WebCrawler项目
java优先级队列;Java多线程处理,线程池,html页面解析等
单例模式enum实现对MySQL数据库操作的优势
开放性问题
- 说一个你曾独立或者作为核心去解决了的一个“有趣有难度”且过程很详细的步步深入优化的技术问题or项目
- 贡献和成果: 核心问题的效率优化过程与方法
- 困难:体现解决问题的方法与能力
- 思路:如果说有趣有难度的项目的话,我想说说kactus的食用油回收项目;在这个项目中参与时间长达半年,技术成长较大;这个项目主要是用来开发一个后台管理系统和Android app,包括司机和经理,用于订单处理和发布;在这个项目中,我参与了整个项目的研发,包括3个主要部分,①通过Java http和WebSocket请求订单数据,利用生产者消费者模式和多线程池提高并发读写效率 ②操作数据库制作RESTful API给移动端app使用 ③移动端app的开发以及二级缓存的优化实现
- 成就感最大的一件事: 比如学习,比赛,需要体现创新性的成果和idea:高德LBS的比赛全国八强,做了什么?为什么有成就感?从日常生活出发想出一个创新的idea,然后结合课程理论进行实践,到最后拿奖这样一个过程。
- 团队合作沟通能力和Team领导力
如何白板写代码???
- Show your idea,,例如白板写代码,遇到新问题即使不知道也可以开始分析,手动画图描述问题的解决过程,从思路到设计测试用例手动输入,一步步归纳出最终解法,转化成代码
- 解决问题的多角度性,从小问题和具体性问题开始入手,一步步递进归纳算法;遇到细节性或者较难实现的问题,可以先声明一个函数及其相应功能,留到后边再完善,代码效率的优化同样可以放到后边再做,思路的流畅性和清晰很重要。
- 主动单元测试,边缘情况测试,null,空字符串,StringUtils.isBlank(str)
遇到生活学习上的印象中最大的困难或者挫折?最后怎么解决的?
- 留学的DIY过程是一个比较困难的过程。为什么?绝大多数人会选择找中介,会省事很多,整个流程和材料的准备都不需要自己动手,但是我选择了自己DIY,所以在这一路的申请过程中遇到不少的挫折和困难,①对于留学的讯息了解不够 , ②准备考雅思 ③文书材料的撰写和修改;
- 最终这一路申请过程中虽然遇到各种困难,但是最终还是受益颇多,其实我本来自己DIY的原因就是我自己觉得申请过程其实是一次很好的审视自我的过程,也为我自己才是最了解我自己的人;不管结果如何,申请这个过程就是一段很好的人生经历,虽然遇到各种困难,但是一一克服,最终也有了一个比较好的结果,拿到了几家不错的offer
最大缺点: 这个问题好难回答啊!我想想……
* 我的缺点是比较专注和执着,比如在技术方面比较爱钻研,有的时候会为了研究一个技术问题,不断地沉浸在里边,不弄明白不罢休,到饭点了都能忘,晚上在公司研究到很晚才撤退。最近出的那个电脑端和手机端同步功能就很好,可以利用零碎时间看博客解决问题了 * 还有就是,工作比较按部就班,总是按照项目经管的要求完成任务。另外的缺点是,总在息的工作范围内有创新意识,并没有扩展给其他同事。这些问题我想我可以进入公司后以最短的时间来解决,我的学习能力很强,我相信可以很快融入公司的企业文化,进入工作状态。我想就这些吧。- 最大的特点或者优势:基础知识+创新能力
- 最感兴趣的课程 本科阶段的话,最感兴趣的是移动端开发,
- 最感兴趣的运动或者业余爱好,长期坚持的爱好: 羽毛球,吉他
- 性格特征
- 对感兴趣的技术会在业余时间去主动学习,刷刷coursera学习普林斯顿的算法课程学习常见算法堆排,买机器学习的书学KNN, 决策树 mapreduce相关知识
- 学习和做工程时愿意深入了解和钻研,多问为什么?例如做Kactus的回收油系统,从做移动端应用开发,我就会去考虑我拿的数据怎么来的,所以就会自己写程序去拿数据,拿到数据存到数据库,怎么做API把数据给移动端用,也自己做了,还会主动考虑着怎么去优化客户端体验,做二级缓存,怎么并行化收发数据来提高效率,怎么比较不同的http库去提高网络请求效率
- 能够发现生活细节,主动去发现问题,提出想法:比如高德项目,项目来源就是出去旅游发现人文景点不知道典故不好玩,看到有导游,怎么不用手机APP来做?,当时也有一些其他想法,比如运动分享记录APP
- 程序员中的外向者,善于与人交流沟通和参与社会活动从本科阶段的支教,社会调研等社会活动可以看出来
- 三个词形容自己:专注深入,发现问题(细心),淡定(有耐心的解决问题)
- 职业规划: :我希望从现在开始,1-2年之内能够在我目前的这个职位上沉淀下来,通过不断的努力后,最好能有晋升,希望3-5年内可以通过在现有的开发岗位上的不断学习和历练,基于现在的项目和平台,包括现在项目所提供的数据背景,条件,能够培养自己的大局观,逐步地从开发到架构,提升自己的业务水平
- 对比一下网易和百度的不同?整体的规范性,团队年轻,沟通非常顺利
- 这么多实习过程中最大的收获?①将理论和实践相结合的机会,了解到为什么学理论,并将学到的付诸于实践,做出真正可用的给成千上万的用户带去便利的产品,是件很有成就感的事情②大公司的开发规范和流程
- 为什么来北京?一方面是因为北京互联网工作机会多,类似于BAT之类的好公司好平台都在北京,是一个增长见识,锻炼自我的环境;二. 最优秀的人也在北京,在这样一个充满竞争的平台里,把握机会,成就自我。
- 你对薪资的要求?关于薪资的话,我个人倒是没有什么特别的要求,首先,我觉得公司提供的平台和成长更为重要,我会更加关注在这个良好的平台带来的自我能力的提升,这个才是比较长远的;另外,我也相信XX作为一家知名公司,在薪酬待遇上肯定不会差,而且校招也有一个合理的市场offer价格,如果公司对我的能力认同的话,肯定能协商出一个双方满意的offer待遇
- 如果公司录用你,你将怎样融入新团队开展工作?作为一个开发工程师而言,进入一个新的工作环境,参与一个新的产品项目我想我首先要积极融入团队,不管是生活上还是工作上,积极主动的沟通才能让我更快地了解整个团队,整个项目,多提问,多思考才能快速进步;然后要对部门的主营业务要有一个了解,了解公司的业务组成部分、业务的发展方向。第二了解我参与项目的开发方式,开发技术栈,架构方式,尽快投入具体的开发工作中。
- 加入新团队的挑战?你怎么融入???新的大模块的从无到有的项目接手的挑战;融入初期的担忧;技术的全局了解和深入快速学习;和团队人员之间的磨合,怎么磨合?
- 对公司的了解如何?希望获得什么?看中技术沉淀和业务前景;加班多么?压力大么?
Tips
- 面试时不要有“我记得 我认为 应该”,可以说我回想一下!一定要慢!声音大!有停顿!
- 不要说自己的工作简单!!!应该说自己快速高效完成,游刃有余,还能挤出时间自学;这是一个有难度的工作
- 压力面试时一定要淡定,即使不会也要有自信,有条不紊的回答问题,遭受质疑时要有理有据地说出自己的观点和自己知道的内容,并主动询问面试官的建议
- 记得问问题。
QA
如果在贵司移动开发部门做开发,主要是做哪些产品研发以及需要用到哪些技术知识和基础,我需要在哪些方面进行努力
面试过程中有没有什么地方讲得太快或者不清楚的地方,我可以补充的
如果可以,可否评价一下面试表现,提供一下您的建议和看法
跨平台应用研发,web轻应用和native app的开发前景比较看法
他们做什么业务,用些什么技术,希望面试者具备哪些方面的能力,对于做这个方向的人有什么建议,觉得我在技术上有什么优点和不足这种