并发级别
蓝色是阻塞的算法,绿色是非阻塞算法,金字塔越上方,并发级别越高,性能越好,右边的金字塔是实现工具(原子操作、锁、互斥体等)
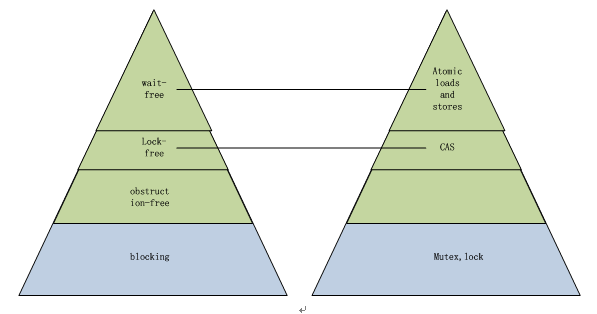
Wait-freedom 无等待并发
每一个线程都一直运行下去而无须等待外部条件,整个流程中任何操作都能在一个有限的步骤内完成,这是最高的并发级别,没有任何阻塞。可以简单认为能够直接调用一个原子操作实现的算法或程序就属于Wait-free,例如:
1 | // 多个线程可以同时调用这个函数对同一个内存变量进行自增,而无须任何阻塞 |
Lock-freedom 无锁并发
整个系统作为一个整体一直运行下去,系统内部单个线程某段时间内可能会饥饿,这是比wait-freedom弱的并发级别,但系统整体上看依然是没有阻塞的。所有wait-free的算法显然都满足lock-free的要求。通常可以通过同步原语CAS实现, 例如:
1 | void stack_push(stack* s, node* n) |
Obstruction-freedom 无阻塞并发
指在任何时间点,一个孤立运行线程的每一个操作可以在有限步之内结束。只要没有竞争,线程就可以持续运行,一旦共享数据被修改,Obstruction-free 要求中止已经完成的部分操作,并进行回滚,obstruction-free 是并发级别更低的非阻塞并发,该算法在不出现冲突性操作的情况下提供单线程式的执行进度保证,所有 Lock-Free 的算法都是 Obstruction-free 的。
Blocking algoithms 阻塞并发
可以简单认为基于锁的实现是blocking的算法。Lock-based 和 Lockless-based 两者之间的区别仅仅是加锁粒度的不同。Lock-based方案就是大家经常使用的 mutex 和 semaphore 等方案,代码复杂度低,但运行效率也最低。
CAS原语
CAS原语负责将某处内存地址的值(1 个字节)与一个期望值进行比较,如果相等,则将该内存地址处的值替换为新值
1 | do{ |
当两者进行比较时,如果相等,则证明共享数据没有被修改,替换成新值,然后继续往下运行;如果不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作。容易看出 CAS 操作是基于共享数据不会被修改的假设,采用了类似于数据库的 commit-retry 的模式。当同步冲突出现的机会很少时,这种假设能带来较大的性能提升。