什么是LevelDB—-LevelDB日知录
一种单机持久化 K/V 数据库。其基于 LSM(LOG Structured Merge Tree) 实现,将所有的 Key/Value 按照 Key 的词法序有序地储存在文件中,具有很高的随机/顺序写性能,非常适用于写多读少的环境。
LevelDB 不是一个 SQL 数据库,它不支持关系数据模型,不支持 SQL 语言,也不支持索引。在同一时刻只允许单个进程(可以是多线程)访问数据库。
LevelDB具备以下特性:
Keys 和 Values 可以是任意的字节序列
数据是按照 Key 排序的
调用者可以提供一个定制的比较函数来决定 Keys 的排序方式。
针对数据库的操作非常简单,i.e.
Put,Get,Delete可以在一次原子的批处理中同时多次修改数据库
用户可以创建 snapshot 保持对于数据视图的一致性
这个数据结构提供前向和后向的迭代器 (iterator)
数据可以自动经过 Snappy 算法压缩
针对于操作系统文件的交互操作,LevelDB 提供给外部用户一个可以定制的虚拟的接口(Env)
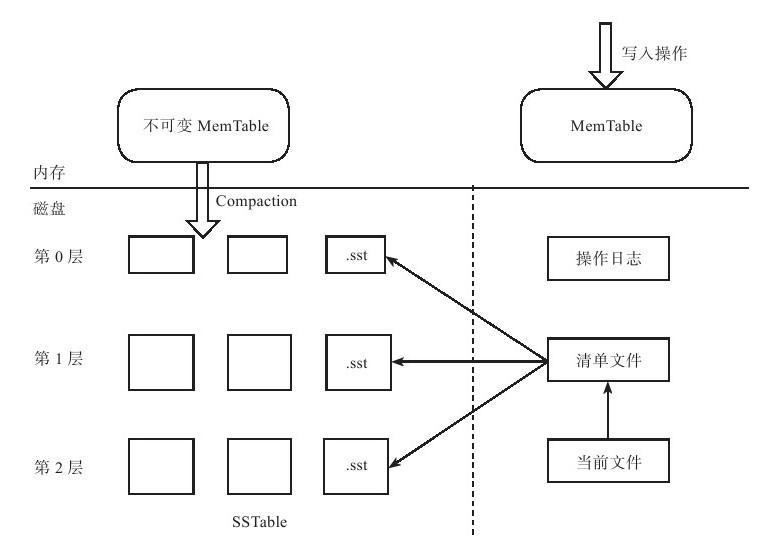
写入流程
- 每次写入一个 Key/Value 对时,首先将该数据追加到 log 中,然后再将其写入到内存的 memtable。memtable 是一个基于 SkipList 的有序的结构,每一个 Key 都会按序组织到 memtable 中。
- 当 memtable 中的数据量达到一定的限制后,其将会转变成为一个 Immutable memtable,同时 levelDB 会新建新的 Log 文件和 memtable 结构用来接收后续的插入操作。内存的 Immutable memtable 将会被后台的线程持久化的存储到磁盘中,生成有序 sstable 文件。
- 磁盘上的 sstable 文件按照 level 的形式组织,从 memtable 序列化得到的 sst 文件位于 level0 层。由于经过 compaction 线程的压缩,文件将不断地从 level n 层向 level n+1层移动。
delete操作
读取流程
leveldb读取数据总是先读取最新的数据,因为有可能插入键值一样的键值对,但是我们查询时是想获取最近插入的数据,所以读取数据时的顺序为:memtable->immemtable->sstable
compaction
minor compaction
就是将immemtable数据写回到磁盘的过程, 也就是L0层sst文件,L0 层的文件个数一般有一个限制
major compaction
即将某一层Ln某个文件和上一层Ln+1的几个sst文件合并的过程,合并时究竟应该选择哪个SSTable与上一层sst文件进行合并以及每层的SSTable空间上限是多大,不同的系统有不同的实现
源码分析
Put函数调用Write函数,触发后台合并操作,DoCompactionWork之前会先调用MakeRoomForWrite函数判断空间是否足够
LSM Tree存储引擎
LSM Tree 的写性能高于 B+ Tree,读性能低于 B+ Tree。原理就是磁盘的顺序访问速度远大于随机访问深度,甚至于磁盘的顺序访问速度大于内存的随机访问速度。
MemTable
核心是Get和Add函数实现对SkipList的操作
Skiplist跳跃表
构建

查找

插入/删除

复杂度

sstable
manifest
versionSet
Key/Value数据存储
Node数据结构
skiplist中的单个node不仅存储了key,也存储了value。dbformat.h文件中定义了跳跃表中的node数据结构,如下表。
| klength | user_key | sequence+type(8byte) | value_size | value |
|---|---|---|---|---|
| user_key 长度 | 用户输入的key | Seq:全局递增的序列号,每一次Put操作都会递增; type:用于判断操作是插入还是删除 | value长度 | 用户输入的value |
skiplist中定义的几种key类型及其组成部分:
- LookupKey/memtable_key:klength + user_key + sequence+type
- InternalKey:user_key + sequence+type
- 不管是memtable还是sstable文件,其内部都是按InternalKey有序的。 比较时先使用InternalKey内部的user_key进行比较,再比较sequence_num
sstable存储结构
Cache
table cache
table cache的key值是SSTable的文件名称,Value部分包含两部分,一个是指向磁盘打开的SSTable文件的文件指针,这是为了方便读取内容;另外一个是指向内存中这个SSTable文件对应的Table结构指针。这样就将不同的sstable文件像cache一样进行管理。
block cache
block cache 的结构其中的key是文件的cache_id加上这个block在文件中的起始位置block_offset。而value则是这个Block的内容
Util基础工具包
coding.cc —- 编解码
leveldb所有数据都是字符形式,即使是整型,也将被转换为字符型存储。这样的好处就是可以减少内存空间的使用。例如,假如有一个int型数据,小于128,存储为整型时,需要占用四个字节,存储为字符型时,只需要一个字节即可。
LevelDB 使用了一种很简单的方案 varint 来节省小整数的存储。对于每一个字节,levelDB 使用其最高的 bit 位来表示当前的编码是否结束,而用低 7 bit 来存储实际的数据。如果最高位为1,表示当前的编码尚为结束,需要继续读下一字节的数据,否则当前的编码结束。示例:
- 对于比较大的数,如果存储的数据如下
1001 0001 1000 1001 0111 1100
^ ^ ^ A: 最高位是1,未结束,实际值是后七位 001 0001
| | | B: 最高位是1,未结束,实际值是后七位 000 1001
A B C C: 最高位是0,结束, 实际值是后七位 111 1100
因此,三个字节拼接应该是 C + B + A :
[1111100][000 1001][0010001] = 2032785 - 对于 [0-127] 的整数,例如:
0001 0001
^ A: 第一字节,最高位为0,表示结束,实际值是 0010001
| 也就是 33
A
arena.cc —- 内存池
Arena内存池实现原理是每次向系统申请4KB大小的一整块内存block, 程序需要内存时,直接从block中获取一部分即可, 这样可以减少系统分配内存次数(new char[]操作), 降低系统分配内存带来的消耗。但是当程序需要一大块内存时(>1024B)时就单独分配一块需要大小的内存,这样也是为了减少系统分配内存的次数。当需要的内存大于block剩余大小而且小于等于1024B时,重新分配一块block,这样会导致有1/4的block被浪费掉。
cache.cc —- LRU缓存
HashTable 和 环形双向链表的结合, hashtable实现O(1)存取时间复杂度; 双向链表实现每次读取或者插入元素都在链表head,每次淘汰链表tail。lru.prev is newest entry, lru.next is oldest entry.
schedule —- 后台任务调度队列
实例分析
RocksDb vs LevelDb
概述
RocksDb新增特性和优化列表
性能优化:
- compaction和memtable inserts操作都多线程化,不止是后台单线程操作
- 减少互斥锁,优化写锁
- Fewer comparator calls during SkipList searches
- Allocate memtable memory using huge page
- Prefix bloom filter
- Optimized level-based compaction style and universal compaction style
- 对SSD存储做了优化,可以以in-memory方式运行
新增特性:
- 列簇(column families)
- 手动压缩与自动压缩并行运行
- Persistent Cache 持久化缓存
- Merge Operators,也就是原地更新,优化了modify的效率
- Transactions and WriteBatchWithIndex
- 单个删除,以及范围删除文件
- Vector-based and hash-based memtable format
- Group commit和AwaitState
- 内存中有多个Immutable memtable
memtable
rocksdb中,memtable在内存中的形式有三种:skiplist、hash-skiplist、hash-linklist。
内联跳跃表(Inline Skip List)
Group commit和AwaitState
RocksDB多个写线程组成一个group, leader 负责 group 的 WAL (write ahead log)及 memtable 的提交,提交完后唤醒所有的 follwer,向上层返回;leader批量提交group所有线程的WAL日志,然后唤醒follower,一起开始并发无锁写memtable(allow_concurrent_memtable_write开关),洗完之后更新线程链表,开始下一轮写入;还支持enable_pipelined_write流水线配置,允许在WAL写完之后开始并发写memtale时就开始下一轮的group。